I.INTRODUCTION
Information on gender is essential for creating investigative leads during the search for an unknown individual [1]. The application of current gender categorization techniques is restricted to crime scenes since they rely on the presence of teeth, bones, or other easily recognizable body parts with physical characteristics that permit gender determination using traditional techniques [2]. Several studies have examined the use of various biometric characteristics, such as the gait, face, iris, fingertip, hand shape, and finger length, to classify gender. In this study, the gender of an individual is established from a fingerprint, and this information can be used to narrow down the suspect list in forensic anthropology [3]. Fingerprint analysis is essential for convicting the perpetrator of a crime. Typically, fingerprints are used for identification or verification purposes, as well as for official documentation. Due to its uniqueness and inability to change during a person’s lifetime, it is now employed as a biometric to classify gender [4]. This is because of the fingerprint’s widespread acceptance, immutability, and singularity [5]. The immutability of a fingerprint is the pattern’s stability over a period of time, and its uniqueness is the variance in ridge features across the entire print. Ridges and valleys on the fingertip form the pattern of a fingerprint [6]. The latter is represented by a white gap between two adjacent ridges, while the ridges are represented by black lines. Uniqueness and tenacity are the two most prominent features of a fingerprint. Individuality refers to the fact that every fingerprint is unique, even when comparing fingerprints from the same person [7]. The persistence characteristic guarantees that a person’s fingerprint core properties never change over time. There are two layers in fingerprint features, namely global and local. The global level refers to the ridges and valleys pattern on a fingerprint and the local level refers to the minute details [8]. The rest of the paper is organized as follows. Section II discusses the literature review. Section III focuses on methodology. Section IV describes the experimental analysis. Section V shows the conclusion and future enhancement.
II.LITERATURE REVIEW
This section focuses on related classification methods and datasets used in fingerprints machine learning approaches.
A.CLASSIFICATION METHODS
Several studies have explored the use of machine learning techniques to classify the gender of fingerprints, using various features and algorithms [9–12]. In one study, Yadav, Jaffery, and Singh [13] developed a multilayer perceptron neural network that used various fingerprint traits, such as white line count, ridge thickness, and ridge-to-valley ratios, to identify gender. To achieve high accuracy, they employed local binary pattern (LBP) and local phase quantization (LPQ) operations, and their model achieved an accuracy of 89.1%.
Another study by Agbo-Ajala and Viriri et al. [14] focused on adapting deep CNN models to gender classification issues. The researchers found that a trained CNN model can outperform newly created task-specific models by utilizing appropriate transfer learning techniques.
Abu Nada et al. [15] utilized a contemporary deep CNN to classify age and gender. Due to limited computer resources and technical obstacles in building larger networks, their model was relatively small. However, the deep convolutional neural network eliminated the problem of overfitting and improved the model’s performance.
Haseena et al. [16] determined a person’s gender based on fingerprint photos using a neural network and an adaptive neuro fuzzy inference algorithm. They used the discrete wavelet transform (DWT) to breakdown the fingerprint image into multiple resolution representations. The researchers discovered that the low-low, low-high, high-low, and high-high subbands of a 2-D wavelet decomposition of an image communicated distinct visual information. Successful gender classification was achieved using SVD, DWT, and a combination of both.
Deshmukh and Patil et al. [17] applied wavelet transform and singular value decomposition to fingerprint scans for gender detection or classification. They presented the success rates of gender categorization using SVD, DWT, and a combination of the two with a KNN classification model and tested the performance of the proposed gender classification technique using an internal database.
Kumar et al. [18] proposed a gender classification model using fingerprints with cross-validation and support vector machines (SVM). Their research was divided into three sections: picture preprocessing, DWT statistical feature computation, and classification of test fingerprints using SVM classifiers with RBF sigma and quadruple kernel into male or female.
The NIST SD27 dataset [19] contains 258,000 fingerprint images from 1,800 individuals. This dataset has been widely used in past studies for gender classification using fingerprints. However, one limitation of this dataset is that it may not be representative of the wider population, as it consists mainly of fingerprints from US citizens who work in fields such as law enforcement and border security. The proposed hybrid method could potentially overcome this limitation by using a diverse and representative dataset of fingerprint images from multiple countries and demographics, which could lead to more accurate and generalizable results.
B.COMMONLY USED DATASETS
The FVC2002 dataset [20] contains 800 fingerprint images from 100 individuals, with 8 images per individual. This dataset has also been used in past studies for gender classification using fingerprints. However, one limitation of this dataset is that it is relatively small and may not provide enough data to train and validate machine learning models effectively. The proposed hybrid method could potentially overcome this limitation by using a larger dataset of fingerprint images, which could lead to more robust and accurate results.
The CASIA-FingerprintV5 dataset [21] contains 13,200 fingerprint images from 660 individuals, with 20 images per individual. This dataset has been used in some recent studies for gender classification using fingerprints. However, one limitation of this dataset is that it only includes fingerprints from Chinese individuals, which may not be representative of other populations. The proposed hybrid method could potentially overcome this limitation by using a dataset of fingerprint images from multiple countries and demographics, which could lead to more generalizable results.
From the overview described above, it is clear that past research has been conducted on extremely limited datasets using standard tools and techniques, and that these methods were inefficient in terms of the time required to train and validate the given data. Therefore, a more robust and generalized framework is required for gender determination using fingerprints. The proposed hybrid method could potentially overcome some of the limitations of past datasets by using a more diverse and representative dataset of fingerprint images, which could lead to more zaccurate and generalizable results. Additionally, the combination of CNN and SVM in the proposed hybrid method could potentially result in a more efficient and effective approach to gender classification using fingerprints.
C.DATASET USED IN THIS STUDY
The SOCOFing dataset [22] is a collection of fingerprints from 600 African individuals, with each person having ten fingerprints and being at least 18 years old. This dataset includes various attributes such as gender, hand and finger names, and artificially modified images using the STRANGE toolkit. The STRANGE framework offers three distinct levels of modification: z-cut, centre rotation, and obliteration. The adjustments were made to high-quality photos that had a resolution of over 500 dpi, resulting in 17,934 images that have simple settings, 17,067 images that have medium settings, and 14,272 images that have complex settings. There is an uneven distribution of modified images throughout the three categories, as some images do not meet the criteria for alteration. The Hamster plus (HSDU03PTM) and the SecuGen SDU03PTM sensor scanners were used to create the original photographs that are included in the dataset. The SOCOFing dataset includes a total of 55,273 fingerprint images, and the resolution of each image file is 1 × 96 × 103 grey pixels in width and height. Figure 1 displays the original fingerprints, whereas Fig. 2 displays fingerprints that have been artificially altered. Both sets of fingerprints can be seen here.


III.METHODOLOGY
The proposed hybrid approach intends to integrate the strengths of SVM and CNN classifiers for fingerprint-based gender classification. CNN is a technique for deep learning that is highly efficient at learning local characteristics and extracting discriminatory data from raw digital images [23,24]. It comprises of numerous interconnected layers, with the output of each layer serving as the input of the following layer. The proposed method utilizes a 5 × 5 kernel/filter to extract the most distinguishable fingerprint picture components. Figure 3 provides a schematic illustration of the proposed technique.
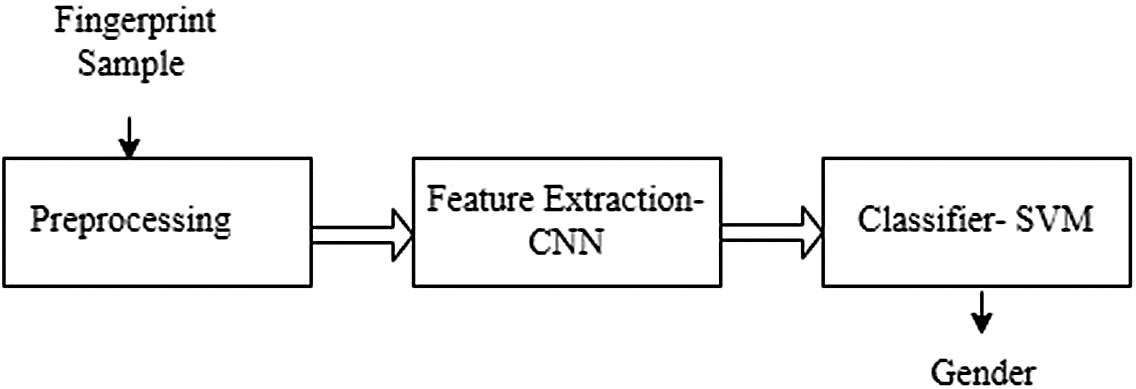 Fig. 3. Schematic diagram of complete workflow.
Fig. 3. Schematic diagram of complete workflow.
The convolutional layer in a CNN applies a set of filters to the input image. These filters slide over the input image and perform a dot product between their weights and the corresponding input pixels. The resulting output is called a “feature map”. The size of the feature map is determined by the size of the given image, the size of the filter, and the amount of padding applied. The output size of the convolutional layer can be calculated as follows:
where input_size is the size of the input image, filter_size is the size of the filter, padding is the number of pixels added to the border of the input image, and stride is the number of pixels the filter moves over the input image at each step.In the proposed method, a 5 × 5 filter is used, so the output size of the convolutional layer can be calculated as
where n is the size of the input image (assuming no padding is used).A pooling layer is typically implemented after the convolutional layer to lower the spatial dimension of the feature maps and improve the network’s computational efficiency. The most used sort of pooling layer is max pooling, which sends the optimum values of a small area (e.g., 2 × 2) of the feature map to the subsequent layer. The output size of the max pooling layer can be calculated as follows:
where input_size is the size of the input feature map, pool_size is the size of the pooling region, and stride is the stride used in pooling.After multiple convolutional and pooling layers, the result is flattened and passed to one or more fully connected layers, which execute a dot product between their parameters and the input to generate a probability distribution for the output classes.
On the other hand, SVM is a machine learning algorithm that aims to represent multidimensional datasets in a space segmented by a hyperplane that separates data components from various classes. SVM classifier seeks to reduce generalization error when applied to unknown data by identifying the best hyperplane that splits the data into distinct classes. SVM’s shallow architecture makes it difficult to learn deep features, although it has been demonstrated to be good for binary classification. SVM seeks to identify the best hyperplane that maximizes the difference between two data classes. The margin is characterized by the distance between the hyperplane and the data points on each side that are closest to it.
Assume we have a training set of n samples, each denoted by a d-dimensional feature vector x(i) and a binary class label y(i) −1, 1. The SVM algorithm attempts to locate the hyperplane wx + b = 0 that classifies the data into two classes such that the distance between the hyperplane and the nearest data points along either side is maximized. We can express the margin as
where ||w|| is the Euclidean norm of the weight vector w. Maximizing the margin is equivalent to minimizing ||w||^2 subject to the constraints that all training examples are correctly classified:This optimization problem can be solved using Lagrange multipliers to derive the dual form of the problem:
where α(i) are the Lagrange multipliers, and the sum is taken over all training examples. The optimal values of w and b can be found by maximizing L(w,b,α) with respect to w and b, subject to the constraints that α(i) ≥ 0 and ∑ α(i) * y(i) = 0.Once we have the optimal values of w and b, we can use them to classify new, unseen examples × by computing:
where sign() is the sign function.In the case of binary classification, the SVM method attempts to identify the hyperplane separating positive and negative samples. Under the requirements that all training instances must be correctly identified, the optimal hyperplane is the one that maximizes the margin. If the training data are not linearly separable, the SVM method can utilize a kernel function to convert the information into a higher dimensional space in which they are separable.
The output of the CNN acts as an input to the SVM classification model in the proposed hybrid system. CNN is used for collecting discriminative features from image features, while the SVM classifier makes the final determination regarding the fingerprint’s gender. The SVM algorithm takes as input the outcome of the final fully connected CNN layer and classifies it as male or female. Assume that the output of the final completely linked layer is a d-dimensional vector denoted by z = hL. The SVM classifier can be represented as the function g(z;w,b), where w is the weight vector and b is the bias term.
The final decision of the hybrid system is made by combining the output of the CNN and the SVM classifier. Let us assume that the hybrid system is represented by the function h(x;θ,w,b), which takes the input image x, and the parameters of the CNN θ, weight vector w, and bias term b of the SVM classifier as inputs. The output of the hybrid system is the final gender classification decision.
We can represent the gender classification decision as a binary variable y, where y = 1 denotes male and y = −1 denotes female. The SVM classifier seeks the ideal weight vector w and bias term b that minimize the objective function shown below.
where C is a hyperparameter that governs the trade-off between maximization of the margin and minimization of the classification error, while I is a slack parameter that permits for some misclassification failures. The first component in the objective function is the regularization term, which penalizes high weight vector w values, and the second derivative is the classification error term.The CNN output serves as input for the SVM classifier. The output of the lth layer of the CNN, represented by hl, is obtained by applying a set of filters W(l) on the output of the (l−1)-th layer hl−1, followed by a nonlinear activation function. We can describe the lth layer’s output as
where * denotes the convolution operation, and σ is the activation function, such as the ReLU or sigmoid function.The final decision of the hybrid system is made by combining the output of the CNN and the SVM classifier. We can express the output of the hybrid system as
where z = hL is the output of the last fully connected layer of the CNN. The hybrid system takes the input image x, and the parameters of the CNN θ, weight vector w, and bias term b of the SVM classifier as inputs, and outputs the final gender classification decision y.The proposed hybrid system combines the strengths of both SVM and CNN classifiers, resulting in a more accurate gender classification system compared to using either classifier alone. The CNN is used to extract discriminative features from the input fingerprint images, while the SVM classifier is used to make the final decision about the gender of the fingerprint.
A.PREPROCESSING
Image size of 96 was set as the target size. A loading data function iterates through each image within the specified path, reads and transforms them to grayscale, and returns an array of pixel values. Consequently, all images will be the same size (96 × 96). The labels were then extracted from the images. Again, the values were turned into an array before being reshaped. The training data were normalized by dividing them by 255, so that the pixel values of images which are in the range of 0 to 255 were scaled down to a range of 0 to 1. A list of labels was converted to categorical values.
B.FEATURE EXTRACTION
Extraction of features is done using a CNN model with two convolutional layers and a maxpooling layer with ‘relu’ activation after each layer. Following that, a flatten layer, a hidden dense layer, and finally an SVM output layer are added. Each convolutional layer (Conv2D) has 32 filters of different sizes (i.e., 3 × 3). Only the first layer contains the input shape. The pool size of Maxpooling layers (MaxPooling2D) is two. There is only one hidden layer (dense), which has 128 units and uses the ‘relu’ activation function. SVM, which works as the classifier, replaces the softmax layer, which is generally employed as the output layer.
C.CLASSIFICATION
The hybrid CNN-SVM model is a machine learning algorithm that combines two types of classifiers, CNN and SVM, to perform classification tasks. The model starts by preprocessing the input data to prepare it for feature extraction. The preprocessed data are then fed into a feature extractor, which extracts the relevant features from the data and records them in matrix form.
The SVM classifier is then used to classify the feature vectors based on the patterns that were learned during training. During the training process, the SVM classifier uses the feature vectors to identify the patterns and relationships that exist in the data. This information is then used to classify new data in the future.
The CNN classifier is used to test the accuracy of the trained SVM classifier. The CNN classifier tests the SVM classifier by using the generated features to classify a new set of data. The testing data are preprocessed in the same way as the training data, and the CNN classifier uses the same feature extractor to extract the relevant features from the data.
Both the training and testing datasets are evaluated for accuracy and performance criteria, and the results are then analyzed. In order to determine the accuracy of the hybrid CNN-SVM model, the projected classifications are compared to the actual classifications. The model’s performance is evaluated by analyzing its speed, memory consumption, and scalability. The outcomes of the research are utilized to develop and enhance the model’s precision and performance.
IV.EXPERIMENTAL ANALYSIS
The performance metrics and the confusion matrix for the CNN-SVM hybrid model were evaluated, and the results have been analyzed as follows.
A.CONFUSION MATRIX
The performance of the hybrid classification model is evaluated using a confusion matrix, as shown in Fig. 4. The confusion matrix summarizes the model’s performance by listing the proportion of accurate and inaccurate predictions for each combination of predicted and actual values. A binary classification model can provide four possible outcomes: true positive (TP), true negative (TN), false positive (FP), and false negative (FN). TP is the number of instances in which the model properly specifies a male as male, TN is the amount of times it precisely recognizes a female as female, FP is the amount of times that it inaccurately specifies a female as male, and FN is the amount of times it inaccurately recognizes a male as female.
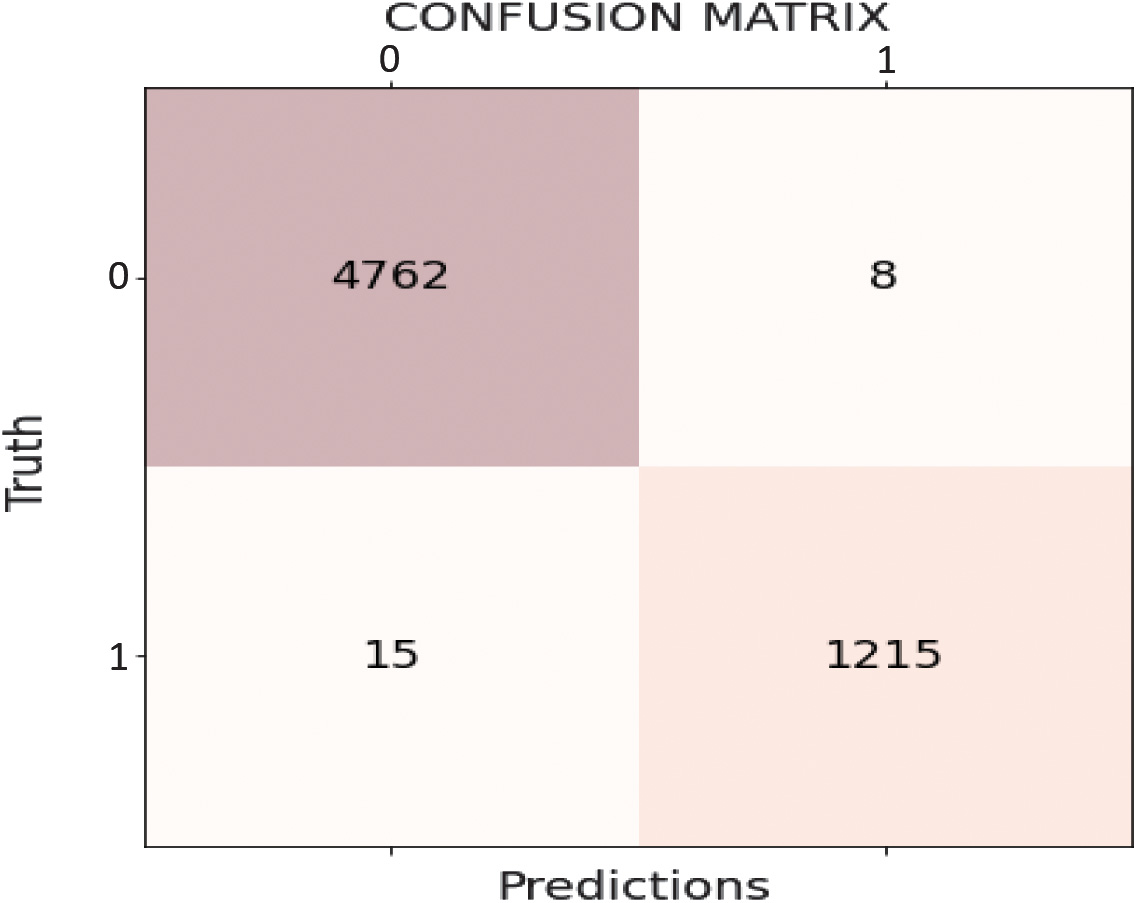 Fig. 4. Confusion matrix for hybrid CNN-SVM.
Fig. 4. Confusion matrix for hybrid CNN-SVM.
Accuracy is determined by separating the number of accurately categorized genders by the overall amount of genders, and the resulting equation is
Recall, precision, and F1-score are evaluation metrics that provide a more detailed assessment of the model’s performance. Recall is the ratio of true positive predictions to the total number of actual positive samples and is given by the equation: The precision is the proportion of true positive forecasts to the overall number of favorable predictions, and it is calculated as follows: The F1-score is the harmonic mean of recall and precision, and the equation for calculating it is A high F1-score of 1.0 indicates a high classification rate, with both precision and recall being perfect. The evaluation metrics provide a more comprehensive understanding of the model’s performance, beyond just accuracy.B.RESULTS OF CONFUSION MATRIX OF HYBRID CNN-SVM
TP: 4762 – This is the number of cases that the classifier properly categorized as affirmative.
TN: 1215 – This is the number of cases that the classifier properly recognized as negative.
FP: 15 – This is the number of cases that the classifier mistakenly classified as positive.
FN: 8 – This is the number of times that the classifier mistakenly classified as negative.
C.PERFORMANCE METRICS
The performance metrics for the CNN model and the CNN-SVM hybrid model are shown in Table I and were compared. The findings show that the hybrid model has improved precision, recall, and F1-score measures, resulting in a testing accuracy of 99%. As a result, the hybrid CNN-SVM model is more effective than the CNN model in handling this imbalanced dataset (Table I, Fig. 5).
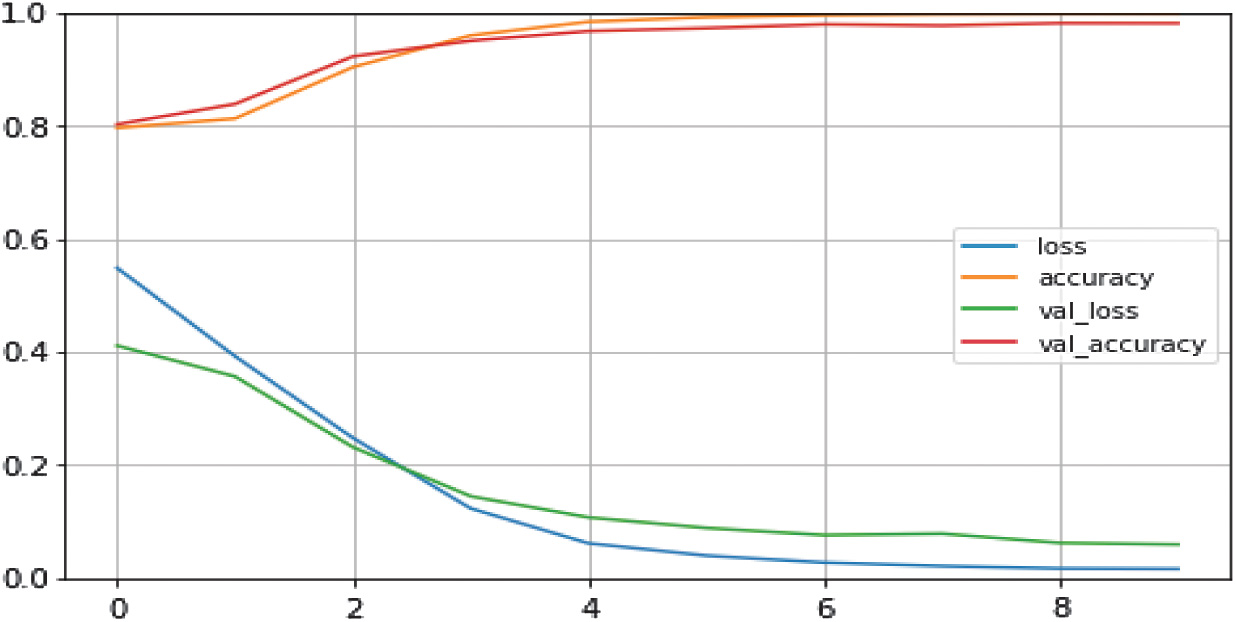 Fig. 5. Learning curve of hybrid model.
Fig. 5. Learning curve of hybrid model.
Table I. Comparison of performance metrics of CNN and hybrid CNN-SVM
| Model | Class | F1-Score | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| CNN | Male | 0.99 | 0.97 | 0.98 | 0.98 |
| Female | 0.97 | 0.97 | 0.97 | ||
| CNN-SVM | Male | 1.00 | 1.00 | 0.99 | 0.99 |
| Female | 0.98 | 0.97 | 1.00 |
V.CONCLUSION AND FUTURE ENHANCEMENTS
Gender identification based on fingerprints is an important and valuable task for enhancing biometric systems. It serves as an important part of numerous applications, such as content-based indexing, human–computer interaction, searching, decision making, demographic research, and surveillance. In this paper, a hybrid CNN-SVM model was presented for gender classification from fingerprints by combining automatic feature extraction with SVM classification. The model combined the best features of CNN and SVM classifiers for identifying gender. Furthermore, the approach encouraged the use of automatically generated features over those that were created by humans. To significantly minimize the present enormous search space in identification and authentication systems, this technique could be employed. According to the test findings, our proposed classification method for the SOCOFING dataset attained an accuracy of 99.25%. The CNN-SVM hybrid model is in its infancy, and further development is possible. In the future, it will be possible to assess the effectiveness of the proposed hybrid model by contrasting it with various data sets. In addition, other optimization techniques may be examined to improve classification performance. This study can be enhanced by incorporating other data-enhancement approaches employing additional geometric changes (e.g., rotation, stretching, and cropping) and histogram-based processes. Additionally, GAN (Generative Adversarial Network) based data augmentation may be examined for classification and detection tasks in terms of picture enhancement and geometrical alterations.