I.INTRODUCTION
Phishing is a sort of cyber-attack where attackers pose as legitimate companies or send phoney emails to mislead victims into disclosing personal information like login passwords or financial data. Due to the attackers’ tendency to create websites that closely resemble authentic ones and their potential use of social engineering to trick visitors into providing their information, these assaults can be challenging to spot. To combat these attacks, organizations and individuals have developed phishing website detection systems. These systems are designed to automatically detect and flag phishing websites and help to protect users from falling victim to these attacks. These systems may use a combination of techniques such as analyzing structure and content and comparing with known phishing website databases using machine learning (ML) algorithms. Phishing website detection systems have become increasingly important sophisticated in recent years with increasing phishing attacks. These systems can help organizations protect their employees and customers from falling victim to phishing attacks and can also help individuals protect their personal information. With more and more activities moving into the digital space, it is more important than ever to have a good phishing website detection system in place.
To develop a malicious website that closely resembles a legitimate website, phishing has recently become a top worry for security concerns. Getting personal information is the attacker’s primary goal. As users are not aware of phishing assaults, the attackers are becoming more successful. It is highly challenging to combat phishing attacks since they prey on user vulnerabilities, yet it is crucial to improve phishing detection methods. Attackers change URLs to appear authentic using encryption and many other straightforward ways in order to escape blacklists. With the help of ML approach, an algorithm can examine different blacklisted and valid URLs and their properties in order to precisely identify phishing websites.
The paper is organized as follows. Section II describes related work. Section III describes methodology used for implementation. The results and discussion are mentioned in Section IV, whereas Section V describes conclusion.
II.RELATED WORK
Pooja and Sridhar [1] introduced a technique for identifying phishing websites by combining convolutional neural network (CNN) with bidirectional long short-term memory (LSTM) networks. They reported enhancement of the efficiency by combining CNNs and LSTMs by extracting features from website content. System accuracy with KNN, Decision Tree (DT), Logistic Regression (LR), and Extreme Gradient Boosting (XGBoost) was 98.40%, 99.05%, 92.08%, and 99.8%, respectively.
Sindhu et al. [2] demonstrated methods to identify phishing attempts using a variety of ML approaches and developed a system using the Random Forest (RF), Support Vector Machine (SVM), and neural network (NN) algorithms in association with backpropagation. The system was trained using a dataset of phishing and non-phishing examples and then tested on new examples to evaluate its performance. Using RF, SVM, and neural networks, accuracy of 97.835%, 97.89%, and 95.444%, respectively, was obtained.
Y. Su [3] explained method to identify phishing attempts using a particular ML approach. The authors developed a phishing detection system using LSTM-RNN algorithms. Reported accuracy of CNN was 97.42% and LSTM was 99.14%, respectively.
Nadar et al. [4] described several ML approaches and techniques to create phishing detection systems and then evaluated their performance using a comprehensive comparison in detecting phishing websites. The paper also outlined various feature extraction techniques used. Challenges and limitations of current methodologies are also described by the authors.
Mandadi et al. [5] described the use of several ML algorithms like DT and RF to create a phishing detection system and evaluate its performance using a dataset from PhishTank website. The authors also described the feature extraction methods used.
A comparison of the results obtained from different techniques suggested RF to be the best method for website phishing detection with an accuracy of 87.0%.
Alam et al. [6] described the use of ML approach. The authors also described various feature extraction methods such as REF, Relief-F, IG, and GR Algorithm. They evaluated the performance of DT and RF to detect phishing websites. In their study, RF provided the highest accuracy of 96.96%.
Saha et al. [7] described deep learning techniques. Author discussed feature extraction techniques such as REF, Relief-F, IG, and GR Algorithm. This research created deep learning-based phishing detection systems that can accurately recognize and report phishing websites.
Patil et al. [8] described a method for detecting and preventing phishing websites using LR, DT, and RF. This system trained the model by feeding it with visual features, heuristic features, and blacklist and whitelist approach. Highest accuracy of 96.58% was seen with RF.
Huang et al. [9] described a method for detecting phishing URLs using a combination of CNN and attention-based hierarchical recurrent neural networks (RNN). The system used LR, RF, SVM, CNN, and RNN models. Highest accuracy of 97.90% was achieved using combination CNN and RNN.
Vilas et al. [10] described an approach for detecting websites using ML. The method involved training a ML model to classify websites as phishing or legitimate based on their features, such as the URL structure, the content of the website, and the presence of certain keywords using ML models.
Chapla et al. [11] described a method for detecting web phishing using ML and fuzzy logic. The method involved analyzing the features of a URL, such as the domain name and the structure of the URL, and using fuzzy logic to determine the likelihood that the URL is a phishing site. Accuracy rate of 91.46% was seen in this study.
Aburrous et al. [12] presented a system using fuzzy techniques. The system used URL-based and content-based features to extract information from phishing websites and then applied fuzzy logic for analysis and classification purpose.
Yang et al. [13] presented deep learning-based system. The system used a combination of visual, structural, and behavioral features to extract information from websites and then applied algorithms, namely CNN and LSTM to classify the websites as phoney or legit.
Kumar et al. [14] outlined a ML-based approach for identifying phishing websites. The system was trained using Amazon.com verification website. Results showed accuracy rates as follows; KNN: 97.99, DT: 98.02, LR: 97.7%, RF: 98.03% NB: 97.18%.
Singhal et al. [15] offered a technique for idea drift detection combined with ML to identify fraudulent websites. The system used URL-based and content-based features to classify the websites. System also monitored the features of the website over time and detects in case of a change or “concept drift” in the feature distribution. Classification algorithms, such as RF, NN, and gradient boosting (GB), were used to classify the website.
In this study, highest accuracy of 96.4% was observed with the GB model.
A study by Pandiyan S et al. [16] reported accuracy 85% with Light GBM. Using UCI dataset, Alnemari & Alshammari [17] compared accuracy of four models for preventing phishing attacks. In their research, RF model showed accuracy of 96.86% and 97.3%, without and with normalization, respectively.
Using three datasets, Mughaid A. et al. [18] demonstrated a very high accuracy with boosted DT suggesting its usefulness in detecting phishing attacks. Awasthi & Goel [19] described a phishing detection model using various classifiers and ensemble model. The analysis was performed by combining UCI dataset and Kaggle dataset. These models were tested with and without cross-validations. Highest accuracy was seen with Extra Trees Classifier.
Mohamed et al. [20] used three approaches; ML approach, heuristic-based approach and blacklist-based approach. Among these, ML showed the best performance. Dutta A. [21] described a phishing detection model using RNN and LSTM. The highest accuracy of 97.4% was observed for PhishTank datasets and 96.8% for Crawled dataset, demonstrating better results than the deep learning methods.
III.METHODOLOGY
The methodology is divided into two parts. Part A describes design section, whereas part B describes implementation section.
A.DESIGN
A proposed methodology for a phishing website detection system can vary depending on the specific system being developed. The suggested methodology and flow are depicted in Fig. 1.
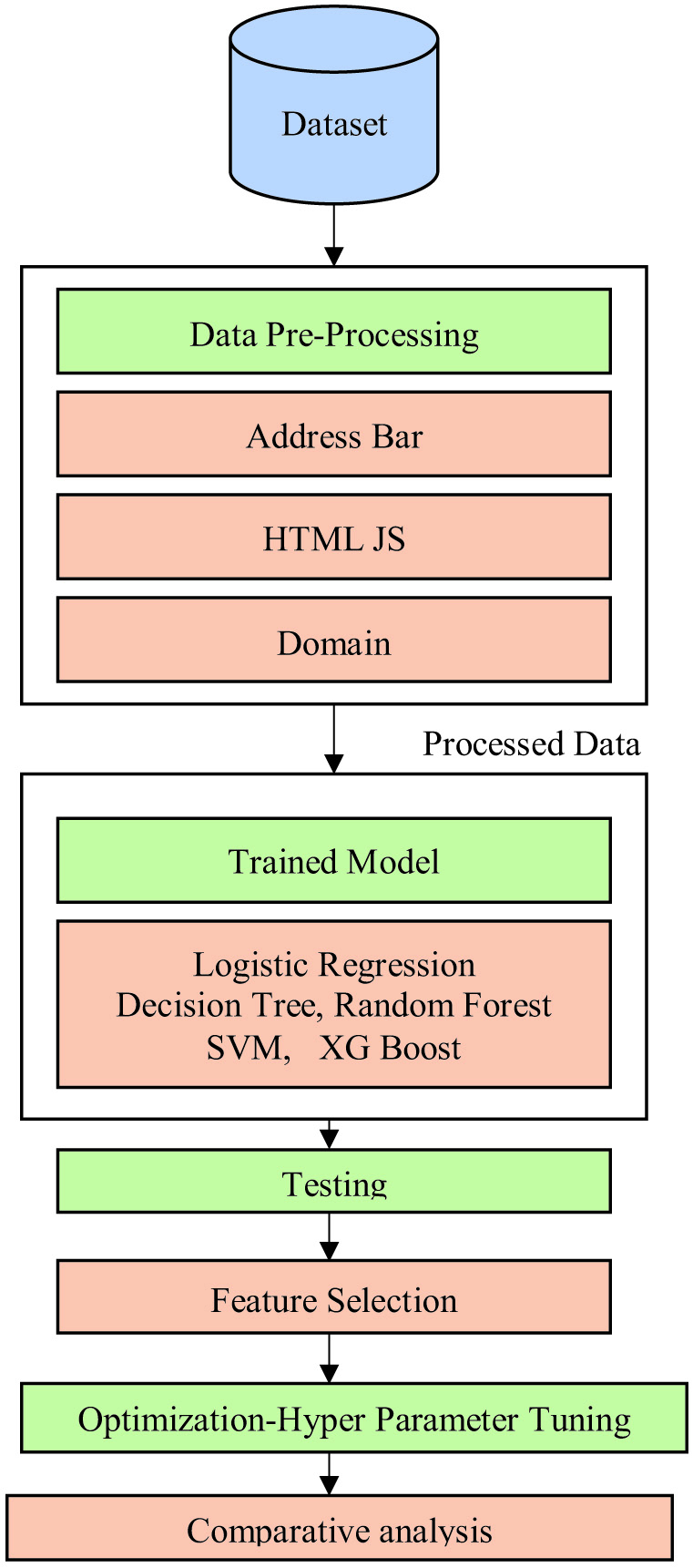
B.IMPLEMENTATION
The proposed methodology worked on two datasets. The proposed system is divided into three phases.
- 1]In the phase 1, we collected a dataset of both trustworthy websites and well-known phishing websites for the system’s training and testing purposes.
Dataset Description
Dataset 1 (PhishTank) consisted 10,000 URLs, evenly split between categories, that is, 5000 phishing URLs collected from PhishTank [22] (https://phishtank.org/developer_info.php) and 5000 legitimate URLs from the University of New Brunswick (https://www.unb.ca/cic/datasets/url-2016.html). The phishing URLs were designated with a label of “1.” Conversely, all legitimate URLs were labeled as “0.” From the datasets, features were extracted using the Python programming language. A total of 25 features were recovered from the jumbled data set, and the model was trained using this set of data. Table I shows extracted features and its data type.
| Sr. No. | Feature | Data type |
|---|---|---|
| 1 | Domain of URL | Character |
| 2 | Having IP Address | bool |
| 3 | Has “@” Symbol | bool |
| 4 | URL Length | bool |
| 5 | URL Depth | int |
| 6 | Has embed domain | bool |
| 7 | Contains “http/https” in Domain | bool |
| 8 | Short Web address Services | bool |
| 9 | Has Prefix or Suffix in web address | bool |
| 10 | Records in DNS server | bool |
| 11 | Network Congestion | bool |
| 12 | Domain Age | Bool |
| 13 | Expiry of Domain | Bool |
| 14 | Redirecting IFrames | Bool |
| 15 | Status Bar Customization | bool |
| 16 | Blocked Mouse Click | bool |
| 17 | Forwarding To Another Web page | bool |
| 18 | google_index | bool |
| 19 | Count (%) | int |
| 20 | Count (?) | int |
| 21 | Count (-) | int |
| 22 | Count (=) | int |
| 23 | Count (.) | int |
| 24 | Count (www) | int |
| 25 | Label | bool |
Dataset 2-UCI, originated from the UCI Machine Learning repository and composed of 11,055 URLs, of which 6157 were phishing examples and 4898 were legitimate. The URL of UCI [23] is https://archive.ics.uci.edu/ml/datasets/phishing+websites. The outcome was categorized as either 1 (not a phishing attempt) or −1 (a phished URL). Every feature of the URLs was depicted as a column with a value of 1 if the URL was fully phished, 0 if it was partially phished or −1 if was benign. UCI included a total of 30 features. Additional features other than from PhishTank were Favicon, Using Non-Standard Port, URL of Anchor, Links in <Meta>, <Script>, and <Link> tags and Abnormal URL.
The webpages in the dataset were then used to extract characteristics, such as URL patterns, website content, and other characteristics. These features were used to train and test the system.
- 2]Phase 2 included model training and cross-validation. In Model training, the system was then trained using a ML algorithm, such as a LR, DT, RF, XGBoost, and SVM on the extracted features and labeled data. The model’s performance was assessed using K-fold cross-validation, which divided the data into 10 folds.
- 3]Phase 3 included feature selection and hyperparameter tuning using grid search. Recursive feature elimination was used to select the most relevant features in the data. This step was important to reduce overfitting and improve the model’s performance. The model’s performance was then optimized through hyperparameter tuning, which involved fine-tuning the model’s parameters. Finally, the selected model was evaluated by using various measures. Classifiers used are mentioned below.
SVM: SVM was used for phishing website detection by training a model to classify websites as phishing or legitimate based on various features such as the website’s URL, the website’s structure, and the website’s content. A dataset of tagged legal and phishing websites was used to train the SVM algorithm in this instance. On the basis of the characteristics learnt during training, the model may then classify new websites as authentic or phishing.
RF: RF can be used for phishing website detection. The algorithm was based on DTs, a type of model that can be used to make predictions by following a series of decisions or “if-then” rules. Multiple DTs were trained on a dataset with labeled genuine and phishing websites in the event of an RF. The final prediction was then created by combining the predictions from each tree.
DT: DT Algorithm created a model of decisions and their possible consequences, represented in the form of a branching structure. A DT model may be trained on a dataset of labeled phishing and legit websites in the case of detecting phishing websites.
LR: LR Algorithm can be used for phishing website detection. By applying a logistic function to the data, the method simulated the correlation between variables. For phishing website detection, a LR model was trained on a dataset of labeled phishing and legitimate websites.
XGBoost: XGBoost is a powerful ML algorithm widely used for classification and regression. It is an implementation of GB framework with DTs as base learners. The main idea behind XGBoost was to iteratively add new DTs to the model for improving its performance. Each new tree was added to correct the errors made by earlier trees in the model. This process is referred to as boosting.
IV.RESULT AND DISCUSSIONS
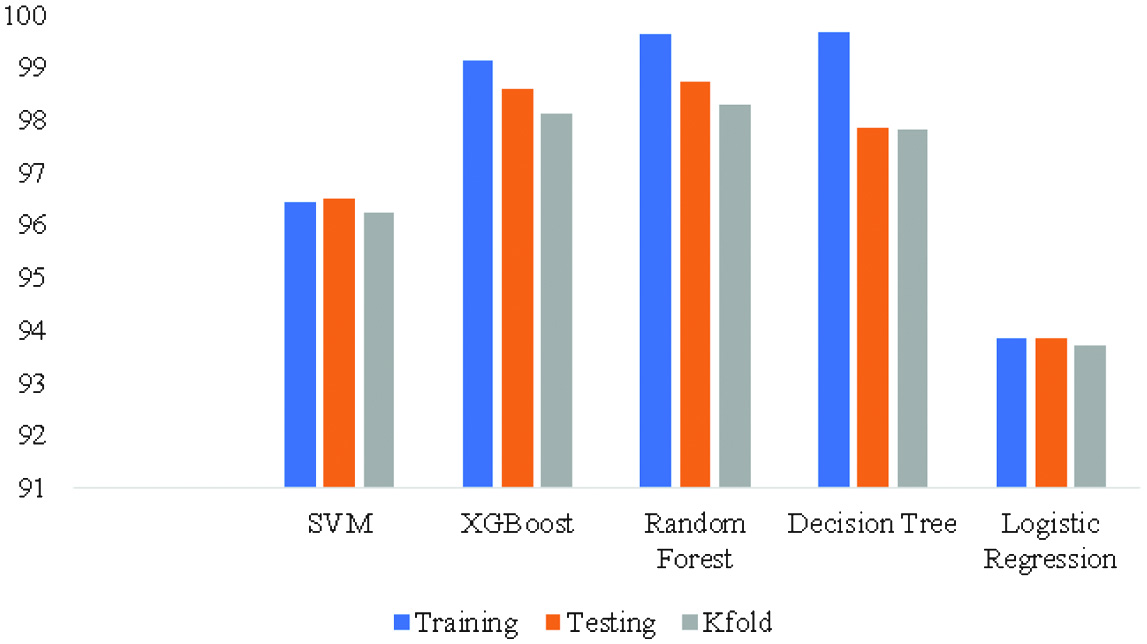
As per the methodology discussed in phase 1 and phase 2, the comparison of training, testing and K-fold accuracy of both dataset is shown in Table II.
Table II. Comparison of models
| Model | PhishTank | UCI | ||||
|---|---|---|---|---|---|---|
| Training | Testing | K-fold | Training | Testing | K-fold | |
| SVM | 96.45 | 96.5 | 96.25 | 95.38 | 95.25 | 94.51 |
| XGBoost | 99.13 | 98.6 | 98.13 | 98.6 | 97 | |
| RF | 99.65 | 98.93 | 96.89 | |||
| DT | 97.85 | 97.84 | 97.06 | 96.19 | ||
| LR | 93.86 | 93.85 | 93.74 | 92.88 | 92.72 | 92.7 |
As mentioned in Table II, the highest training accuracy on PhishTank was observed in DT. Highest testing and K-fold accuracy on PhishTank were observed with RF. The lowest K-fold accuracy was seen by the LR model of 93.74%. The graphical representation of each classifier is shown in Fig. 2.
Feature selection is a vital step. Considering this, feature selection using recursive feature elimination method was used. Hyperparameter tuning helps to optimize the proposed methodology. Comparison of K-fold, feature selection, and hyperparameter tuning using Grid Search CV on PhishTank are mentioned in Table III.
Table III. Comparison of K-fold, feature selection, and hyperparameter tuning
| Model | K-fold | Feature selection | Hyper parameter tuning |
|---|---|---|---|
| SVM | 96.25 | 96.50 | 98.30 |
| XGBoost | 98.13 | 98.55 | 98.55 |
| RF | |||
| DT | 97.84 | 97.95 | 97.95 |
| LR | 93.74 | 94.00 | 94.00 |
Highest K-fold, feature selection, and hyperparameter tuning accuracy of 98.31%, 98.75%, and 98.80%, respectively, were observed in RF model. The lowest feature selection accuracy was seen with the LR model at 94%. The graphical representation of each model is shown in Fig. 3.
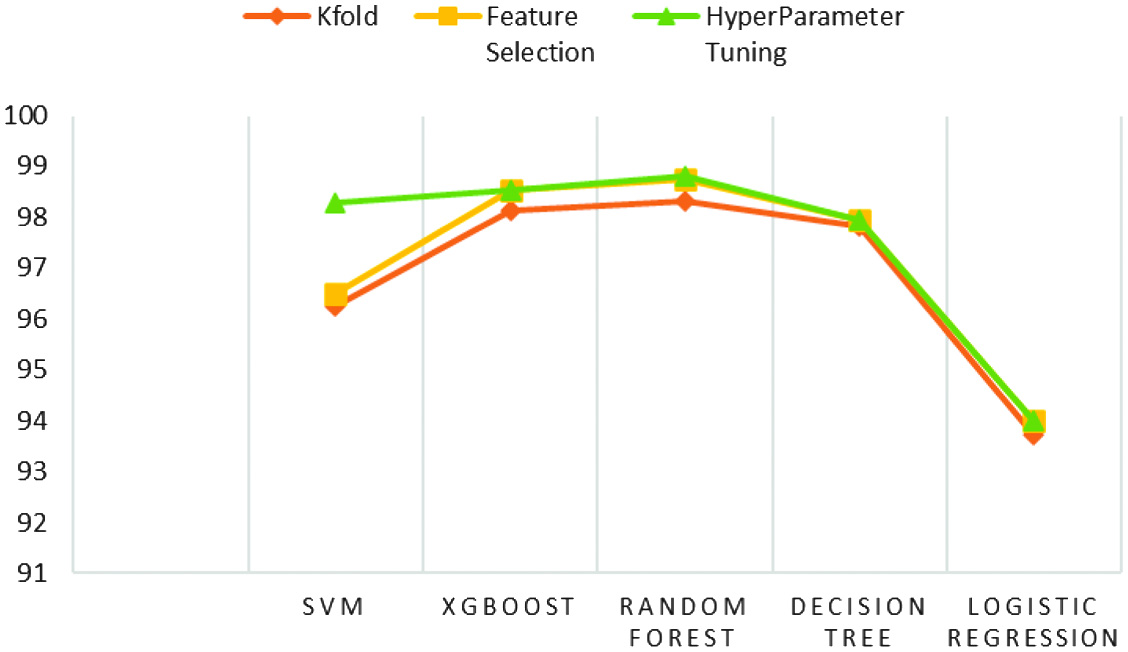 Fig. 3. K-fold, feature selection, and hyperparameter tuning accuracy.
Fig. 3. K-fold, feature selection, and hyperparameter tuning accuracy.
Table IV shows comparison of K-fold, feature selection, and hyperparameter tuning accuracy on UCI. The highest K-fold accuracy of 96.1% was seen with XG boost model while maximum feature selection and hyperparameter tuning accuracy were shown by RF classifier. The lowest accuracy was shown in the LR classifier.
Table IV. UCI – comparison of K-fold, feature selection, and hyperparameter tuning accuracy
| Model | K-fold | Feature selection | Hyper parameter tuning |
|---|---|---|---|
| SVM | 94.51 | 95.07 | 95.98 |
| XGBoost | 97.00 | 97.30 | |
| RF | 96.89 | ||
| DT | 96.19 | 96.83 | 96.83 |
| LR | 92.70 | 92.76 | 92.76 |
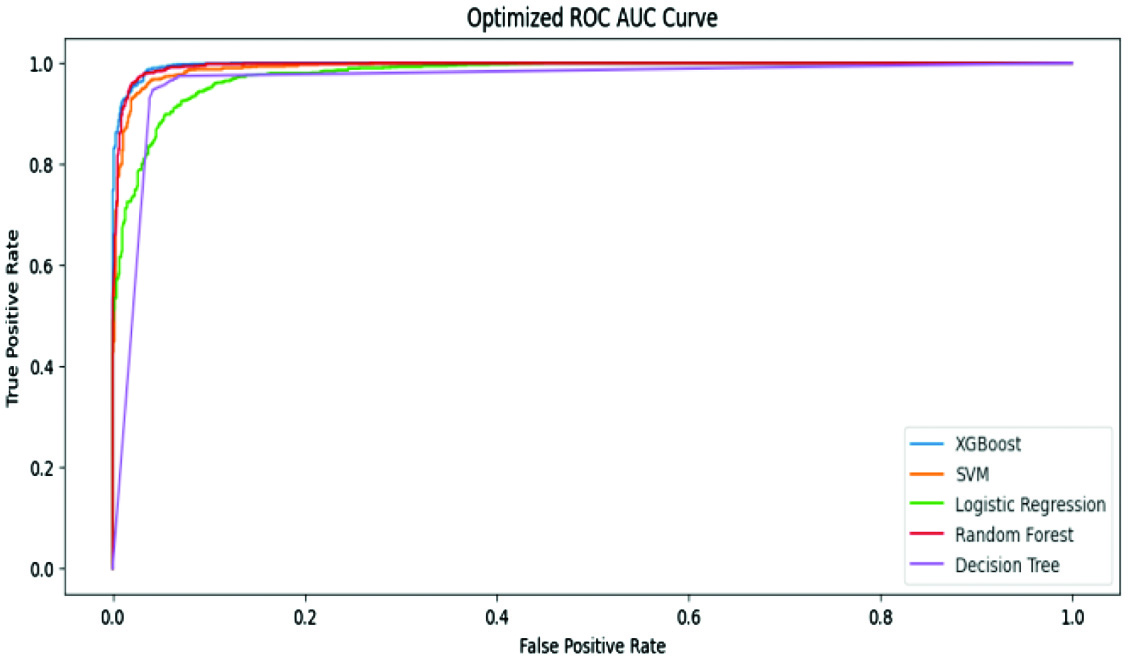
Figures 4 and 5 represent ROC curve analysis of both PhishTank and UCI.
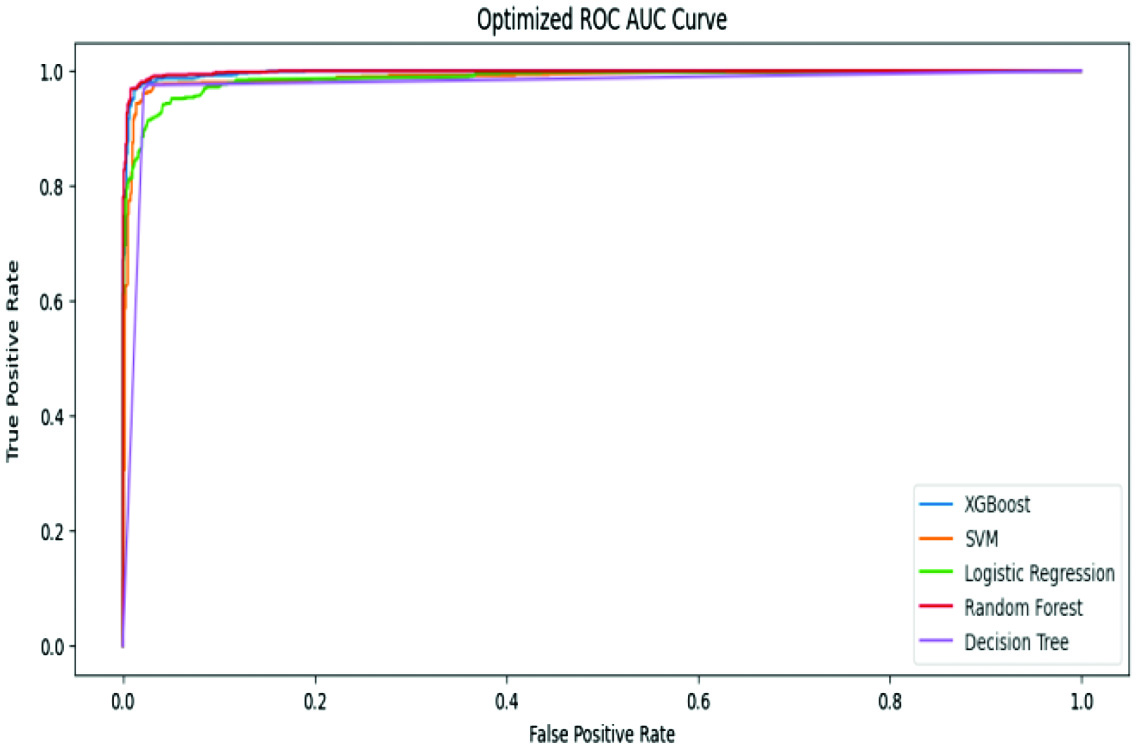 Fig. 4. PhishTank – ROC AUC curve.
Fig. 4. PhishTank – ROC AUC curve.
Performance analysis on various measures observed by the best model on PhishTank and UCI dataset is shown in Fig. 6.
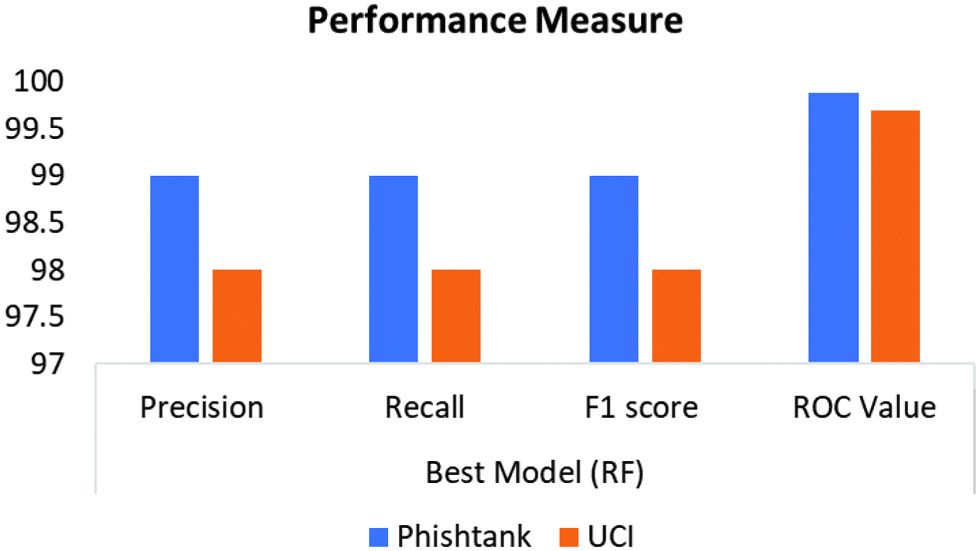 Fig. 6. Comparative performance analysis-PhishTank and UCI dataset.
Fig. 6. Comparative performance analysis-PhishTank and UCI dataset.
A.VALIDATION WITH CONTEMPORARY RESEARCHER
The results of our proposed methodology validated with the contemporary researchers who worked on PhishTank are mentioned in Table V. The proposed methodology yielded good results with an accuracy of 98.80% in comparison with the other researcher.
Table V. Validation – PhishTank
| Ref no. | Model | Accuracy |
|---|---|---|
| Mandadi et al. [ | RF | 86 |
| Alam et al. [ | RF | 97 |
| Huang et al. [ | CNN+RNN | 97.9 |
| Kumar et al. [ | RF | 98.03 |
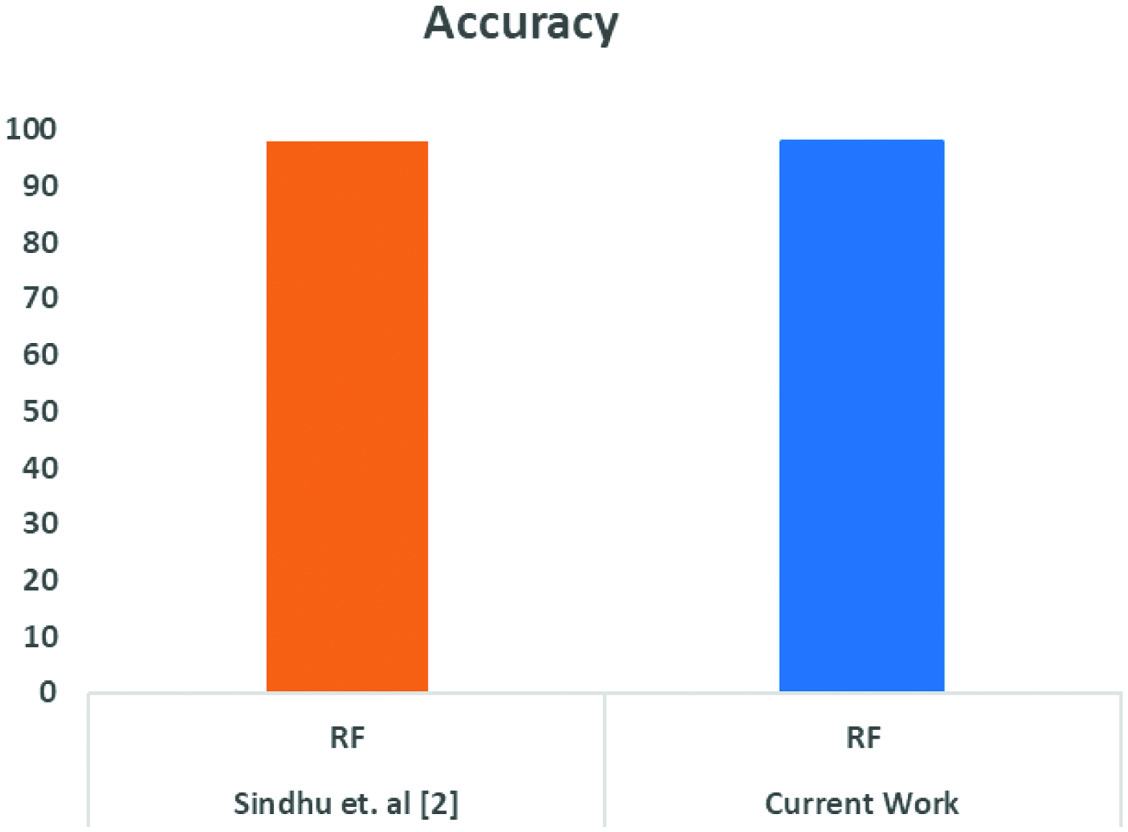
Proposed approach results tested on UCI dataset and validated with the existing researcher are shown in Fig. 7. Methodology adopted by current work of RF classifier and existing research results are similar.
IV.CONCLUSION
It is important for a phishing website detection system to have a high accuracy rate of detecting phishing attempts. The objective of this research was to detect phishing attacks by analyzing patterns using ML. We observed that the use of feature selection and hyperparameter tuning can help to improve the model accuracy. Proposed ML-based framework outperformed in terms of accuracy precision, recall F1-score and ROC value on both datasets. Validation of ML algorithms outperformed other state-of-the-art methods yielding high results in terms of accuracy. Performance measures in proposed framework helped in detecting phishing attacks.