I.INTRODUCTION
The fundamental driving force behind education and teaching is teachers. With the change in the economic climate following the reform and opening up, physical education (PE) in China has entered a new historical stage, concentrating more on enhancing teaching quality [1]. Strengthening the structure of the teaching team and improving the PE teaching staff in schools are the two most important steps to improving the quality of instruction. With the rapid development of the Internet and IT technology, as well as the impact of the epidemic, the frequency and ratio of enterprises and job seekers to recruit and search for jobs on the Internet are constantly increasing, and the phenomenon of “information overload” is gradually appearing in the human resources information on the Internet (such as job resumes and jobs). In response to the phenomenon of “information overload,” the traditional portal classification and search engines are weak in the face of the surge of data and the unclear needs of users. Although many recruitment websites recommend jobs to job seekers by means of classification, search engines, and recommendation algorithms (RAs), how to make personalized job recommendations according to job seekers’ career development needs has always been a problem that troubles people [2]. The selection of candidates who are an “instant match” for the requirements of the school, however, necessitates the employment of RAs due to the large amount of data and information available [3]. Traditional recommendation techniques for job searchers that rely on browsing and searching do not satisfy their demands well and do not enable customized recommendations. The fact that many job applicants misjudge their own abilities is a widespread issue. Job searchers are blinded in the job search process because they are unable to truly grasp both themselves and the role [4]. Traditional algorithms used in schools do not account for the particulars of the work, which makes it challenging to match the proper person to the position. Traditional RA either focuses exclusively on the match between the user’s background talents and the job and overlooks their career development needs [5,6] or just uses the user’s previous data as a screening feature and disregards the match between their background abilities, career development needs, and the job. This study will innovatively consider the above factors and construct a recommendation model under the framework of a collaborative Bayesian variational network, so as to provide a more accurate realization of human-post matching.
The article structure consists of five parts. Section II discusses the related works, providing an overview of the existing literature on sports talent recommendation models. Section III presents the proposed sports talent recommendation model based on Bayesian variational network and career needs. The model’s architecture and training process are described in detail. Section IV presents the experimental results and analysis to verify the effectiveness of the proposed model. Finally, the research work is summarized, and future directions are provided for this study in Section V.
II.RELATED WORKS
To handle the massive data in the information age, RAs are used in various fields. In order to leverage data and people analytics (PA) and to maximize the business value of the talent, a recommendation system for personalized workload assignment in the context of PA was proposed. The system followed a novel two-level hybrid architecture. Experimental results showed that the system was effective and could create significant business value and help managers make better decisions [7]. In order to improve the problem that the resources recommended by human resources were shorter in length and contained less information about the actual human resources, a human resources RA based on improved frequent itemset mining (IFIM) was proposed. The algorithm could call a dataset containing a single item and mine human resources to improve the frequent itemset. The algorithm also used the positive matrix factorization model and the algorithm of collaborative filtering to divide the recommendation mechanism to avoid the data loss problem in the recommendation process. Test results showed that the RA recommended the longest length of resources and contained the most information, which was beneficial to the talent recruitment of enterprises [8]. Zhu utilized machine learning (ML) techniques for modern enterprise management and analysis of human resource data. This study designed and implemented a salary prediction model based on ML for human resources. The model used a gradient descent algorithm and backpropagation neural network to improve the accuracy of the prediction model. The experimental results showed that the model had a recommendation accuracy of 89.98% and a validation accuracy of 84.05%. This study could reduce the number of HR operations and improve the efficiency of HR management work [9]. Zhang studied the privacy problem of the Top-N RA with an integrated neural network. The algorithm achieved the purpose of protecting people’s privacy by interfering with Internet signals. The experimental results showed that the Top-N RA had an information protection rate of 88% when the usage level of the Top-N RA was F. When the signal interference strength was 5 and the RA was F, the privacy protection of Internet users was the best. The study had important value in protecting people’s privacy [10]. Liu et al. designed a graph convolutional network report recommendation algorithm based on user information fusion to address the issue of traditional reporting tools being unable to independently recommend relevant business information to enterprise users. The performance of the algorithm was studied on both public and marketing business datasets, and the results showed that compared with existing algorithms, the proposed algorithm had a significant improvement in recommendation performance, which can empower the management of power enterprises, Assist enterprises in digital transformation [11].
Bayesian algorithms are commonly used RAs and there are many research results in the area. Praveen used the plain Bayesian algorithm and ML techniques to build a model to predict the likelihood of an individual developing heart disease in the next 10 years. The model predicted heart disease through various cardiac attributes of the patient. The parsimonious Bayesian algorithm was used to categorize the data. Experimental results showed that the plain Bayes algorithm achieved about 81.5% accuracy on test data [12]. Amin et al. proposed a method that integrates different techniques to overcome the challenges of dealing with nonlinear, non Gaussian, and multimodal behaviors, where artificial neural networks are used for recognition and Bayesian networks are used for fault detection. The results show that this method can provide more flexible and widespread applications [13]. Lopes used Bayes for solving the step size selection problem of the least mean square (LMS) algorithm. The study used coefficient estimation of error variance (qw) and probability density function (PDF) estimation to calculate the optimal step size for LMS. Bayesian estimation of PDF from data and assumption of Gaussian reference and measurement noise signals were also used. The experimental results showed the effectiveness of the method to select the optimal step size of the LMS algorithm [14]. Liu et al. designed a personalized book recommendation system for child–robot interaction environments in order to help children read books more conveniently. The system consisted of using a new text search algorithm and a reverse filtering mechanism. The system was based on the user interest prediction method of the Bayesian network (BN), and based on the children’s fuzzy linguistic inputs, the system recommended the books that they were interested in. Experimental results showed that the recommendation system had high performance and was simple enough to run on mobile devices. This study provided an intelligent assistive system for children’s reading, which was conducive to promoting children’s interest in reading [15].
To sum up, the RA has achieved good application results in medicine, enterprise human resource management, short video platforms, and other fields, and the Bayesian algorithm is one of the most commonly used RAs in previous research. The focus of researchers has gradually shifted from the application of traditional mature RAs to the improvement and application of deep learning RAs. It can be seen that compared with traditional RAs, deep learning RAs are more likely to bring breakthroughs in the field of human resource recommendation. However, previous studies often ignore the long-term career development needs of talents when recommending talents and do not take the regional occupational social–economic status into consideration. This study will innovatively consider the professional social and economic status factors and other demand factors and construct a talent recommendation method suitable for PE teachers.
III.AN APPROACH TO BUILD PET TEAM
A.TEXTUAL FEATURE VECTORIZATION AND DEMAND RECOGNITION MODELS
In order to construct a RA, data pre-processing such as collection, conversion, and cleaning of sports talent CV and job information text is required, followed by a feature vectorization operation. This operation converts the attribute values in the original data into something more amenable to algorithmic processing [16]. The method chosen for the feature vectorization process is the Word2Vec algorithm, an algorithm developed by Google for computing and processing word vector calculations [17]. Word2vec is a natural language processing algorithm that produces word vectors that can be applied to subsequent tasks such as classification and clustering. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic word texts. Under the bag-of-words modeling assumption in word2vec, the order of words is unimportant. After training, the word2vec model can be used to map each word to a vector, which is the hidden layer of the neural network and can be used to represent word-to-word relationships. Compared to other methods, its accuracy is higher while minimizing computational costs. The algorithm has a continuous bag of words (CBOW) model and a Skip-gram model [18]. The CBOW model uses a continuously distributed contextual description and shares a projection layer for each word, so all words are projected onto the same projection layer to obtain the average of their vectors, and its training complexity is shown in equation (1).
In equation (1), is the size of the projection layer of the model and is the number of units to be evaluated in its output. Skip-gram models attempt to classify the maximum number of other words in the same sentence [19]. The algorithm uses each current word as input to the classifier and selects a specified region for prediction before and after the current word. Because the more distant words are less relevant to the target word, the more distant words are less likely to be selected with lower weights in the learning process [20]. The training complexity of the model, , is shown in equation (2).
In equation (2), is the maximum interval between words, which usually takes the value of 10. Considering that the RA of the study mainly focuses on the background ability information, career development expectations, and job requirements of the user’s CV, only the data feature vectorization operation is performed here for this information. The flow of this operation is shown in Fig. 1, with steps such as stemming extraction, lexical reduction, construction of dictionaries and tree structures, counting word frequencies, generating binary codes, initializing vectors, and training vectors [21].
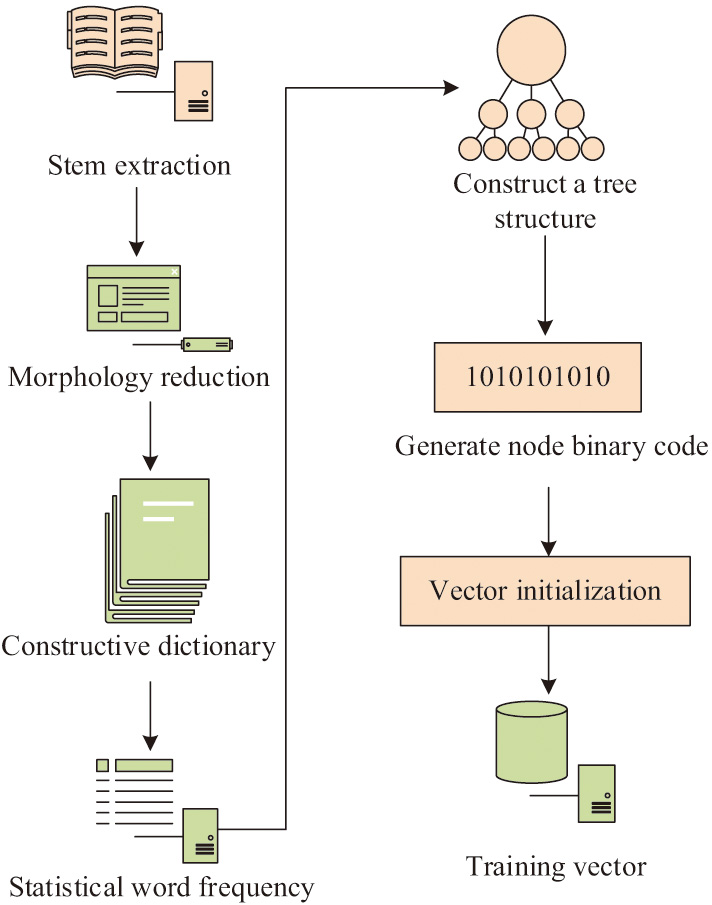 Fig. 1. Text feature vectorization processing flow.
Fig. 1. Text feature vectorization processing flow.
This study will implement automatic text slicing based on the ICTCLAS system, extracting discourse tags and word frequencies occurring in the text, and then using word2vec from the gensim toolkit for training. It is assumed that two job seekers with identical backgrounds simultaneously submit their CVs to the platform for employment, but different career development expectations, i.e. the desired local Social Economic Statu (SES), make them require different job recommendation results [22,23]. SES is an overall measure of an individual’s economic and social status that blends concepts from economics and sociology. The SES of PE teachers in each region is taken into consideration when seeking employment, and when building PET teams, local communities need to match their own economic conditions with the SES of PE teachers, so this study takes the SES of PE teachers in each region as one of the important factors in matching talents to jobs. Based on previous research results, this study uses local income and educational attainment in the sector as secondary indicators of SES, and the secondary indicators are downscaled to obtain the SES index in a comprehensive calculation. The final SES results will be incorporated into PET’s job search demand variables, laying the foundation for subsequent job matching [24].
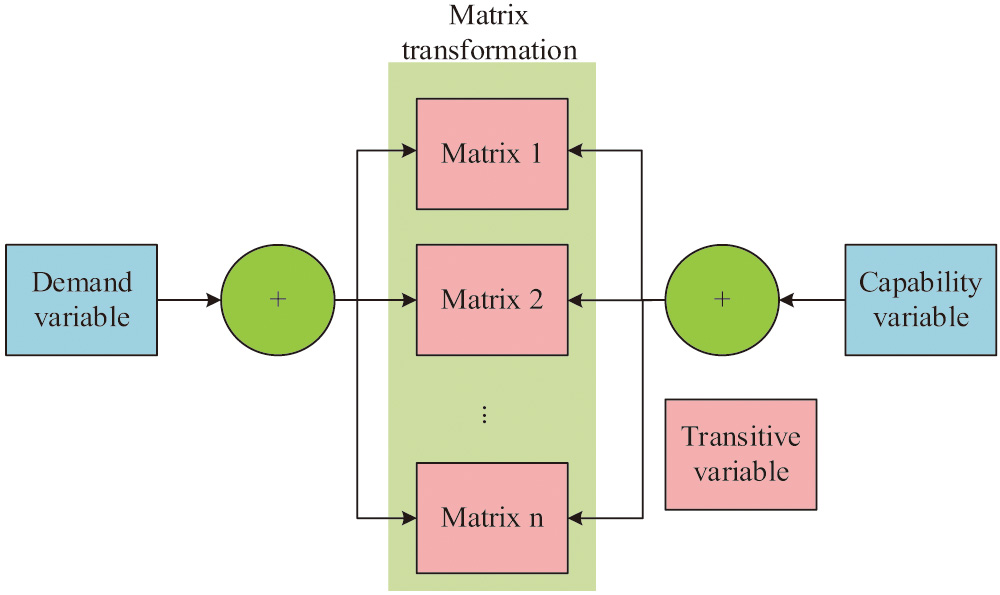
Therefore, the study designed a needs identification mechanism as shown in Fig. 2, linking the needs variable and the competency variable through the user’s previous job browsing history and CV submission information. The mechanism also links competency variables and transfer variables, with each dimension of the competency variables being a representation of a modeled topic. The modeled topics have a transformation pattern, and if there are transformation patterns, the topic matrix is transformed times, with each transformation resulting in a consequent change in the scale of the topic.
B.RECOMMENDED MODEL FRAME CONSTRUCTION
Based on the latent factor model (LFM), the study assumes that both sports talent and HR examine jobs based on two perspectives: the user’s demand perspective for the job and the job attribute perspective. Therefore, a K-dimensional shared space is constructed, denoting the hidden variable of user , and denoting the hidden variable of job . The vector normally shows that the rating of on can be obtained from the inner product of the hidden variables. When the range of the ratings is [0,1], the smaller the value the less interest or concern the user has for the post. Setting the prior of the hidden variable of the post to a normal distribution, this equation is given in equation (3).
In equation (3), is the unit matrix and is the job variable parameter. In conventional LFM, the potential user requirement variables are also derived from the normal prior. However, common sense dictates that the user’s ability and background have a major influence on the job selection process. Understanding the user’s competencies plays a very important role in modeling their needs.
In traditional LFM models, conventional priors are also used as predictor demand variables. However, from a general point of view, the qualifications of job applicants have an important influence on job selection, and understanding their competencies is key to modeling the needs of job applicants [25]. Based on this idea, a variational auto-encoder (VAE) is used to represent the competencies of the job applicant using the competency hidden and the latent Dirichlet allocation (LDA) model, and a parametric network is used to generate the competency profile of the job applicant .
In equation (4), is the competency profile and is the parameterized operation. On the other hand, as mentioned earlier, users with similar competency profiles and therefore similar potential competency variables may differ considerably in their job selection, depending on their career development plans. It is not appropriate to recommend jobs based only on competency profiles. Features can be extracted from historical behavioral data in order to identify the user’s career development goals.
Those with similar professional background information will have very different job choices depending on their individual career plans. It is not appropriate to recommend jobs based solely on the quality of one’s abilities. It is, therefore, possible to extract the characteristics of users’ career development needs by analyzing their historical behavior. Let the need identification mechanism be , and transform the original ability variables into career need variables by considering the user’s historical behavior, desired area SES, and ability variables, the process is shown in equation (5).
In summary, this study proposes the PETRA of the demand-aware collaborative Bayesian variational network (DCBVN), which considers the flow of the algorithm as shown in Fig. 3, including raw data collection and pre-processing, training the model and generating the recommended blending results, etc. Firstly, after the raw data is collected, preprocessing operations such as cleaning, normalization, and discretization are performed on the data. Then, customer data and job data are represented and statistically analyzed to obtain statistical features for input into the RA algorithm. The RA algorithm is based on a demand oriented collaborative Bayesian network framework, fully considering the user's own career development needs and the degree of matching between professional abilities and job positions. Finally, the algorithm utilizes VAE and LDA to semantically express user capabilities, and uses a parameterized network to generate capability profiles to generate recommendation results that blend user and job requirements.
 Fig. 3. DCBVN algorithm flow chart.
Fig. 3. DCBVN algorithm flow chart.
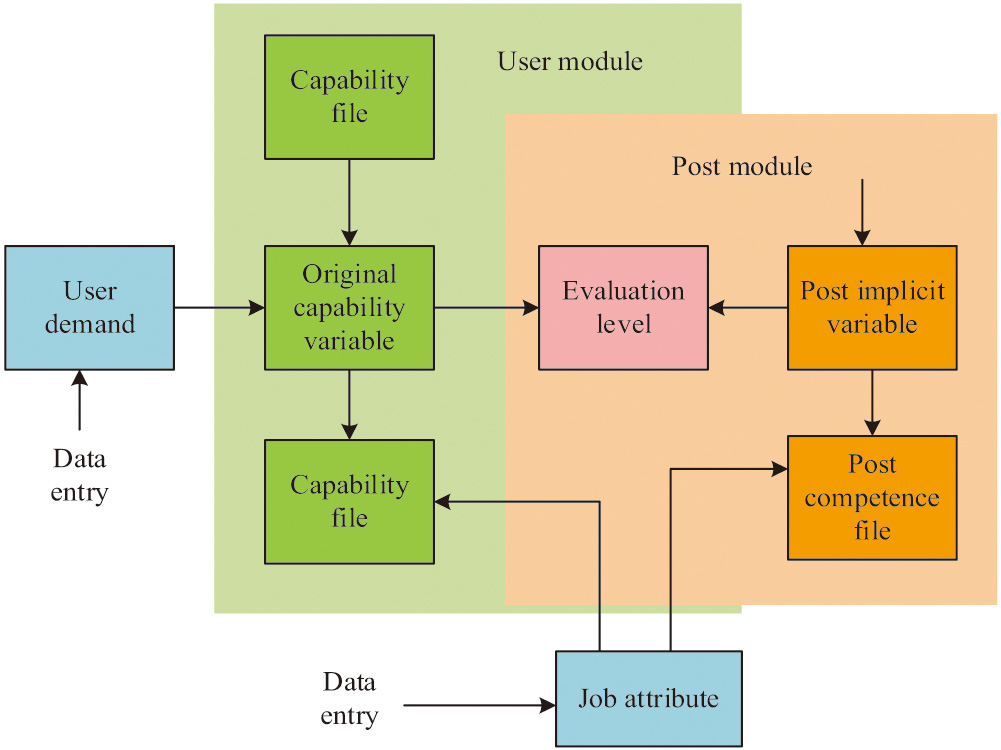
A recommendation framework was constructed based on the DCBVN algorithm, which has a graphical model as shown in Fig. 4, with two modules, the user module and the job module. The user needs and job requirements are oriented for joint modeling, and the matching results of job seekers and jobs are generated through Bayesian collaborative filtering.
IV.ANALYSIS OF THE EXPERIMENTAL RESULTS
In order to verify the effectiveness of the proposed model, the effect of each parameter on the performance of the model was first analyzed. The parameters chosen are the weight for recommendation accuracy, the balance parameter for focusing on individual or group information, and the number of demand topic transitions for the demand recognition model. The recommendation accuracy of the model is then compared between the training and test sets, and finally, the recommendation performance is compared between the normal use case and the sparse case. Under normal circumstances, since it is not appropriate to train and recommend the model with future job options, the training set and the test set are built separately in chronological order. In the sparse case, the data are divided similarly to normal, but only 30% of the posts are selected for each user to form the training set. In the DCBVN framework proposed in this study, the parameter is set to 50 to compare with other methods.
The experiment is a comparison experiment, comparing the model of this study with the recommendation system for PA of the literature [7], the human resource RA based on IFIM of the literature [8] and human resource RA based on ML of the literature [9] were compared. Precision and recall were chosen as the recommendation performance evaluation metrics. Recall was calculated for the number of previous successful recommendations/total number of successful recommendations and was expressed using R@X, where a smaller X value indicates better performance of the model. The experimental data were selected from 500 sets of historical user data from the WiseNews recruitment platform. Half of the data was pre-processed and used as the training set and half as the test set. The dataset of the experiment contains the user’s major, education, career intention, vocational skills, expected salary, and other information and is sensitized (Table I).
Table I. Experimental environment
| / | Software and hardware environment | Version/model |
|---|---|---|
| 1 | IED | IntelliJ IDEA |
| 2 | GPU | NVIDIA GTX 1660 Super |
| 3 | CPU | Intel Core i5 10400F |
| 4 | HDD | SMI L06B B0KB 128GB |
| 5 | Operating System | Win 10 |
| 6 | Programming developer | Python v3.11.3 |
| 7 | RAM | 16GB |
The effect of each parameter on the recall of the recommended model is shown in Fig. 5, with parameter and parameter having a small effect on the recommended performance and parameter having a relatively large effect. The numerical values of the parameters indicate whether the demand recognition mechanism of the model pays more attention to the information of individuals or groups.
 Fig. 5. Influence of each parameter on the recall rate of recommendation model.
Fig. 5. Influence of each parameter on the recall rate of recommendation model.
The model recall is always highest when is taken as 0.2. When is small, the model in this study tends to be less accurate and the recommended recall is smaller, and the model does not converge as well at this point. The best performance of the model is achieved when the value of is taken as 100, and is taken as 200, which is the best number of pattern transitions for the model. However, value of 0.2 does not mean that the model pays more attention to group information than to individual information. The norm of group behavior data is smaller than that of individual behavior data due to the normalization operation of group behavior data when processing data. This means that the vector length or size of the group behavior data in the matrix is smaller, and the structure of the model will be simpler with less parameter information. Therefore, there will be a phenomenon that the recommended results of the model have a high recall rate. The numerical change of the parameter indicates that the focus of the model is adjusted to favor prediction accuracy or reconstruction error. When the value of the parameter is reduced, the model will reduce the penalty for prediction loss, and the performance of the model will be biased toward the prediction accuracy. Fig. 5(b) shows that the model performs best with a value of 100. Fig. 5(c) shows that taking 200 is the optimal number of mode transitions for the model. Therefore, in subsequent experiments, the model parameters , , and were set to 0.2, 100, and 200, respectively.
The recommendation accuracy of each model in the training and test sets is shown in Fig. 6. The accuracy of the model is always the highest in the training set, which is around 0.6, and in the test set, which is 0.68. The accuracy of the model decreases to a certain extent as the number of samples increases, but the decrease is small, which shows that the performance of the model is relatively stable. Fig. 6(a) shows that the recommended accuracy of PA will increase slightly when the training sample is increased to 150, but its overall accuracy is still not high, and its performance in the early stage of training and testing is the worst. Figure 6(b) shows that there is little difference in performance between ML and IFIM in the test set. It may be because ML got better training results in the training set and made up the gap with IFIM. Compared with these models, the performance of this model is the best in both the training set and the test set.
 Fig. 6. Recommendation accuracy of each model in training set and test set.
Fig. 6. Recommendation accuracy of each model in training set and test set.
The recall of each recommendation method in the normal case is shown in Fig. 7. The normal case is defined as 80% of the historical platform usage data for each job seeker selected for training and testing. The models in this study had R@20, R@60, R@100, and R@200 as 0.2566, 0.3580, 0.4399, and 0.5888. For the PA model, R@20, R@60, R@100, and R@200 are 0.18, 0.19, 0.22, and 0.36, respectively. The ML model is 0.20, 0.30, 0.38, and 0.44 respectively. The IFIM model is 0.22, 0.33, 0.38, and 0.52 respectively. Relatively speaking, the recall rate of the model in this study has always remained at the highest level, which is higher than other models.
 Fig. 7. Under normal circumstances, the recommended recall rate of each model.
Fig. 7. Under normal circumstances, the recommended recall rate of each model.
The recall of each model in the sparse case is shown in Fig. 8. The sparse case means that 40% of the historical data of the job applicants were selected for training and testing. The values of R@20, R@60, R@100, and R@200 of this model are 0.2490, 0.3210, 0.3950, and 0.5336, respectively. For PA model, R@20, R@60, R@100, and R@200 are 0.1884, 0.1968, 0.2365, and 0.3545, respectively. The ML models are 0.1968, 0.2987, 0.3745, and 0.43, respectively. The IFIM models are 0.21, 0.323, 0.37, and 0.51, respectively. The recall rates of the model in the sparse case are still consistently the highest compared to the other methods, which shows that the model has a better recommendation performance. Compared with the normal case, the recall rate of the model decreased slightly, but the decrease was low, which shows that the model performance has some stability.

V.CONCLUSION
The study incorporated the expected SES, competency background, historical data, and other personal career needs and job requirements of PE teaching talent in order to attract teaching talent and better build the school’s PET team, and then constructed a DCBVN recommendation model. The accuracy of the model used in this study consistently improved the most in the comparison experiments, and it was recommended to maintain an accuracy of roughly 0.6 in the training set and 0.68 in the test set. The experimental results showed that the model performed well in terms of talent recommendation, which was advantageous for the accurate matching of PE teaching talents and teaching positions, the growth of the PE teaching team in schools, and the development of a model for intelligent teacher team building. The family history and personality of job searchers were not taken into account, despite the fact that this study took into account aspects affecting the hiring process, including the aptitude and career needs of job seekers and work criteria. To make the model recommendations more applicable, efforts will be made to quantify these variables in the next study.