I.INTRODUCTION
Translation, as a medium of communication between cultures, should effectively convey the emotional content contained in the original text. This requires translators to accurately understand the emotional expression of the original text and find the most expression appropriate way in the target language, which is the emotional beauty requirement of English translation [1,2]. In the increasingly intelligent modern society of translation, machine translation is an important tool for English translation. In translation, sentiment analysis is crucial for whether machine translation can achieve emotional beauty. Emotional analysis can help machine translation systems better understand the emotional meaning of the original text. This can accurately convey and preserve the emotional information contained in the original text, avoiding emotional loss or misinformation caused by language and cultural differences and improving translation quality [3,4]. However, traditional analysis methods mainly focus on the emotional feature extraction and the classifier combination selection. The combination of different classifiers has certain impacts on the results of sentiment analysis. These methods often fail to fully utilize the contextual information of the text when conducting sentiment analysis on text content, and there is a problem of ignoring contextual semantics. Therefore, the classification accuracy has a certain impact [5–7]. Long short-term memory (LSTM) is a commonly used structure that can capture long-term sequence information, making it suitable for regression and classification with contextual contexts [8,9]. Therefore, this study innovatively focuses on topic and sentence information in the sentiment analysis using LSTM as the baseline model. Therefore, an intelligent text sentiment analysis method based on translation-based long short-term memory (TB-LSTM) is proposed. This study aims to develop a comprehensive and reliable intelligent text sentiment analysis model, providing more accurate sentiment classification and recognition. By combining translation techniques and deep learning models, the designed model effectively utilizes semantic and contextual information, thereby improving the problems existing in traditional sentiment analysis methods. Furthermore, the article attempts to classify multidimensional emotions and improve the ability to classify complex emotions.
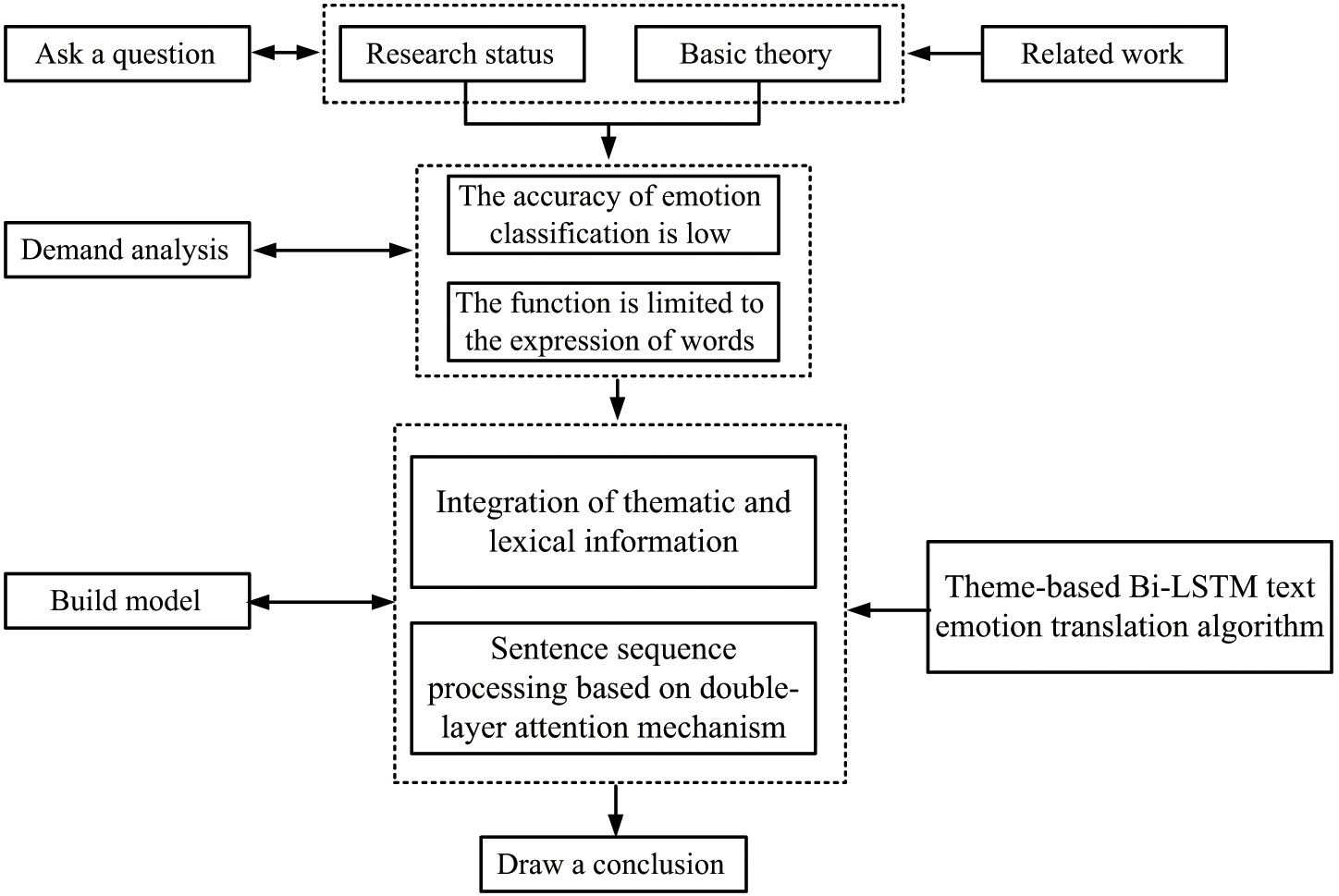
The rest of this paper is structured as follows. Section II describes the related work. Section III introduces the relevant theory, model structure, and specific algorithm steps. Section IV presents the experiments that are used for verifying the validity of the model. Section V concludes the paper. Figure 1 illustrates these parts of the work and their relationships.
II.RELATED WORKS
Isnain A-R et al. used K-nearest Neighbor Algorithm (KNN) to study the sentiment on government online education policies in Twitter. This study used word frequency reverse text frequency to assign weights to vocabulary and classify emotions in online learning. The data from 1825 tweets were used from Indonesia between February 1, 2020, and September 30, 2020. These experiments confirmed that the method proposed in this study could achieve an accuracy of 87%, a recall of 86%, and a false alarm rate of 0.12%. According to category analysis, the general public tended to have a positive emotional inclination toward online learning. This study was feasible for promoting the implementation of government online education policies [10]. Liu C et al. developed a two-layer LSTM based on implicit expression images to address the difficulty of text emotion recognition caused by the complex grammatical and semantic differences in Chinese. When constructing features, the model converted emoticons into corresponding emotion words as extended features. When analyzing Chinese text on the Internet, the accuracy rate of this method reached 0.95, which could complete the sentiment analysis task more effectively [11]. Shamrat F et al. used supervised KNN to classify vaccine sentiment during the pandemic era. This algorithm divided data into three categories: positive, negative, and neutral. After analysis, people tended to have positive emotions toward various types of vaccines. This study provided support for analyzing people’s emotional attitudes toward vaccines [12]. In response to the security risks in social media platforms such as Weibo, Boukabous M et al. proposed a fusion algorithm that combined a dictionary and pre-trained language models to analyze user emotions on social platforms. This method was based on a dictionary approach to annotate the Twitter dataset, dividing the data into two categories: those with normal emotional tendencies and those related to crime. Finally, the language model was trained using the annotated corpus. These experiments confirmed that the proposed algorithm was superior to existing algorithms in many aspects, with an accuracy of 94.91% and an F1-score of 94.92%. It was beneficial for helping social platforms detect potential security threats [13].
Parimala M proposed an emotion analysis method to analyze the emotional impact of a disaster on people in a certain area, analyzing the real emotions on social media after and during the disaster. This method used LSTM with word embeddings to extract historical information and contextual keywords, classified tweets using network-generated keywords, and identified sentiment scores for each position. These experiments confirmed that the method improved the average efficiency by 1% for two different categories, with an average of 30% for multiple categories. This model could help the government to prevent the impact of disasters in specific areas [14].
In response to the imbalance in text emotion recognition, Pavan Kumar M et al. integrated emotion dictionaries with bidirectional LSTM. This study proposes a context-based subjective word recognition algorithm, which weights subjective words and complete words. The text-based oversampling algorithm fully utilized the semantic information in the text when generating new text samples. These experiments confirmed that this algorithm had certain practical value for emotion recognition of imbalanced texts [15]. Dirash A R et al. reviewed various methods and algorithms for text sentiment analysis. This study used different machine learning algorithms to detect emotions in text and compared the experimental results of these methods. These experiments confirmed that LSTM had stronger performance and less training time. Compared with LSTM, other methods such as RNN and CNN are inefficient. This study provided direction for the selection of baseline models for sentiment analysis work [16]. Huang F et al. proposed a novel text sentiment detection model to improve the text sentiment classification performance of LSTM. This model integrated emotional intelligence and attention mechanisms. This study utilized emotional intelligence to design an emotion-enhanced LSTM, which enhanced the feature learning ability of LSTM. This model introduced a topic-level attention mechanism to adaptively adjust the weights of text hidden representations. These experiments confirmed that this method could effectively improve the performance of sentiment classification. Its performance was superior to comparison methods, improving the sentiment classification ability of LSTM [17].
In summary, although researchers are consciously expanding the dimensions of sentiment analysis, the results of applying models to sentiment analysis are not ideal. The finer the sentiment dimension, the lower the accuracy of sentiment classification, and it is difficult to achieve 50% results. Therefore, more time and energy are needed for in-depth research on sentiment analysis. In existing research, external information can promote the effectiveness of text classification. However, its function is limited to vocabulary expression and neglects the assistance of thematic information in the acquisition and understanding of textual emotions. Therefore, this study innovatively combines topic vectors with word vectors to achieve better emotion recognition results. The rest of this article is structured as shown in Fig. 1. Section II describes the related work. Firstly, the relevant theory, model structure, and specific algorithm steps are introduced. Then, experiments are done to verify the validity of the model.
III.TEXT SENTIMENT CLASSIFICATION BASED ON TB-LSTM
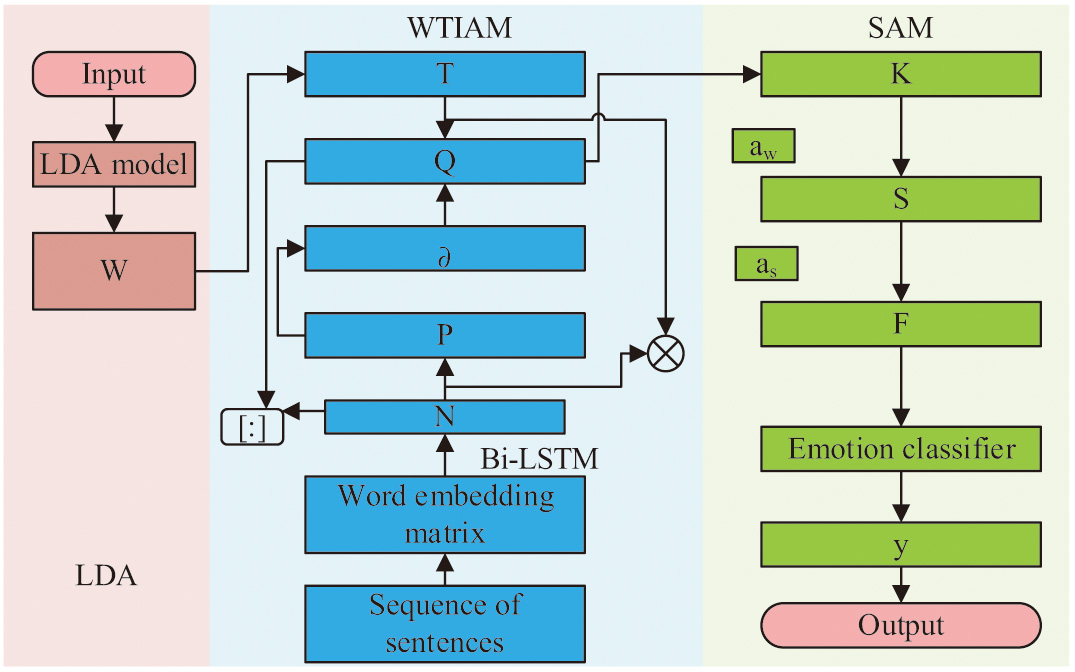
In this section, a textual sentiment classification model incorporating latent Dirichlet allocation (LDA), bidirectional LSTM, and two-layer attention mechanism is proposed. The first part deals with word-level sequences based on TB-LSTM. The second part introduces the two-layer attention mechanism and constructs a complete model framework.
A.INTEGRATION OF THEMATIC AND LEXICAL INFORMATION
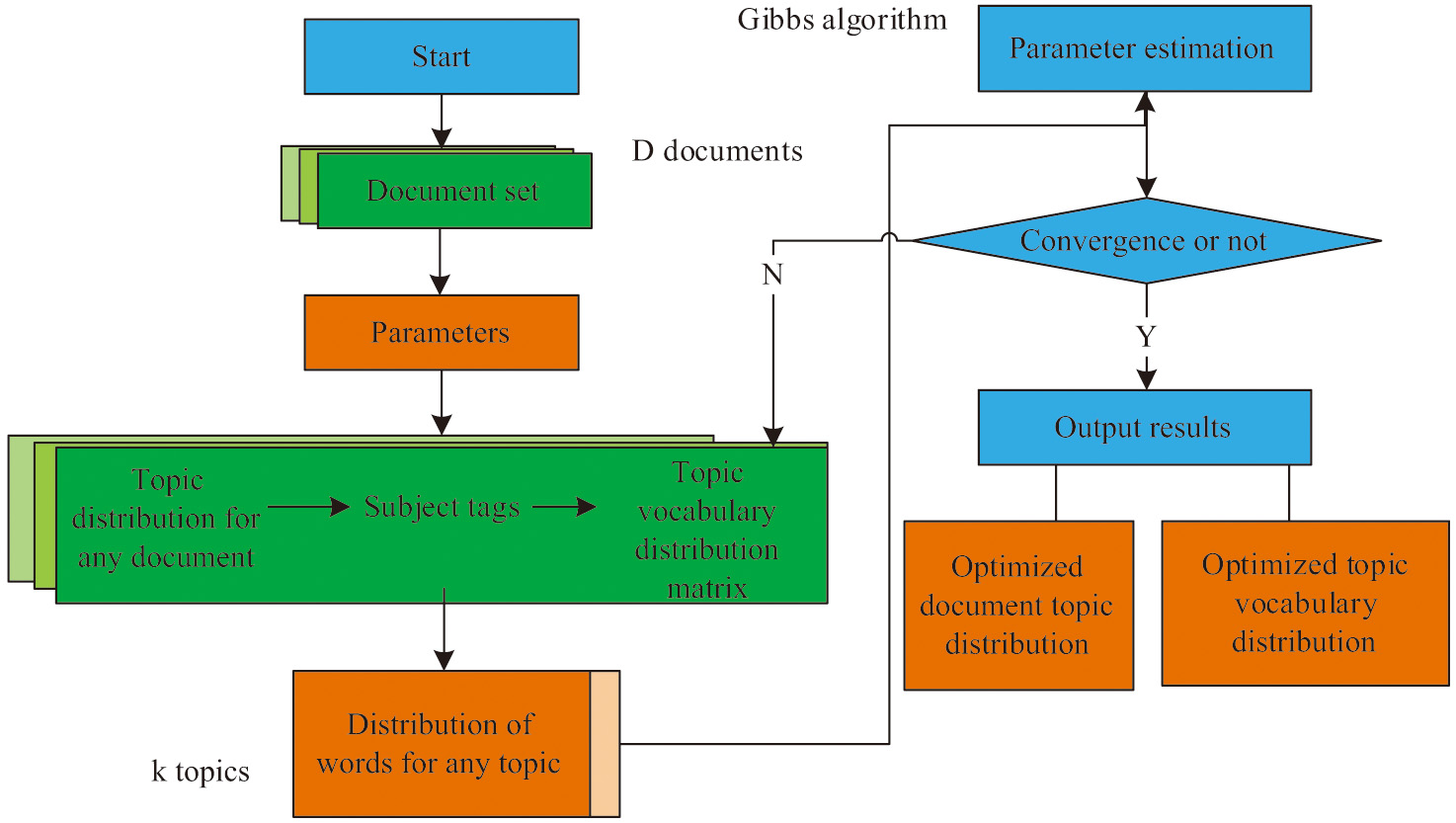
Topic modeling is one of the popular methods for learning text representation, which has been frequently used in natural language processing fields such as text clustering, text partitioning, and sentiment analysis in recent years. It is used as an external auxiliary knowledge to improve the model complexity and achieve better classification results. LDA is a well-known topic model in text modeling. LDA can mine topic and is unsupervised, not relying on training samples. It does not have domain transfer issues and has good domain adaptability. Therefore, this study utilizes the probability computing power of LDA to obtain the topic information of the document [18–20]. LDA assumes that the total number of documents in a document set is D, with topics and non-repeating words. Figure 2 shows the principle of LDA. It takes text as input and obtains the probability of each text appearing in the topic and the probability distribution of each word appearing in each topic through statistical analysis of the text. LDA is a complete Bayesian probability graph model. When inferring parameters, it is necessary to first obtain a posterior distribution and then use Gibbs sampling method to estimate its parameters until it converges. The optimal distribution of text themes and keywords is ultimately determined.
Firstly, it should transform the topic vocabulary distribution matrix extracted from the LDA topic model into a low-dimensional topic vocabulary embedding matrix through a fully connected layer. Thus, the topic information representation vector with the same dimension as the lexical hidden semantic information representation vector in equation (1) is obtained.
In equation (1), is a function. is the probability distribution of the topic vocabulary. Then, a low-dimensional topic vocabulary embedding matrix is set as . The implicit semantic information matrix of the vocabulary is . The relationship between a single vocabulary and the topic is calculated. Based on the , the matrix is reconstructed to obtain the embedding matrix for vocabulary topics. Finally, and are connected together to obtain a lexical level semantic representation, denoted as . In this process, the first step is to preprocess the input document and organize it into a sequence of form words. Then, the vocabulary in the sequence is processed into word vectors through Word2vec and then input into Bi-LSTM to obtain the matrix .
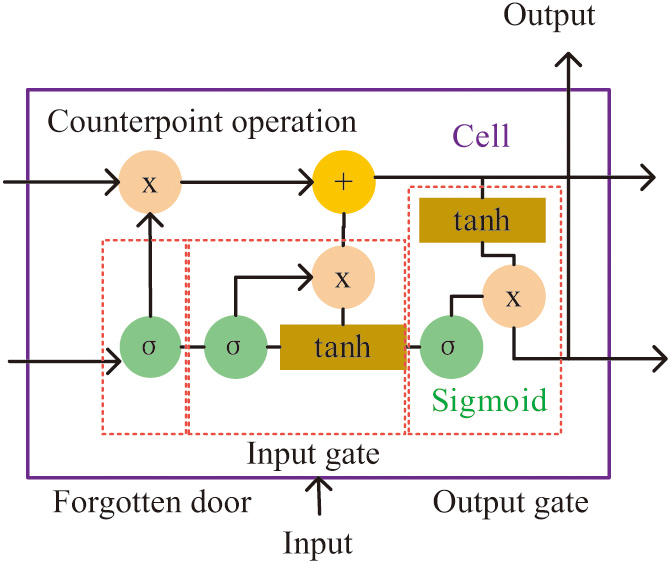
LSTM is a variant of recurrent neural networks. It overcomes the shortcomings of traditional methods, which can handle long sequence data [21]. Figure 3 shows the basic units of LSTM. It is a long-term cellular state that consists of three components, namely three gates. By controlling the “gate,” it achieves an organic fusion of short-term memory and long-term memory, to some extent overcoming the loss. When information passes through the forgotten gate, it determines which information to ignore and activates the function to indicate whether the output can be maintained. Then, the information that needs to be saved for the subsequent calculations. Next, the previous data are integrated to form new data, and the data that have already been used in the previous layer are deleted. Then, the output information is filtered using the Sigmoid function. Finally, the Tanh function is used to execute the output [22].
LSTM can effectively overcome the shortcomings of traditional recurrent neural networks such as information loss and excessive gradients. However, it can only capture the content mentioned earlier well, while ignoring the content in the following text [23]. Therefore, this study uses Bi-LSTM as a benchmark to train it and improve its processing ability for complex text data, while overcoming its inherent shortcomings. Figure 4 shows the structure of Bi-LSTM, consisting of a forward LSTM and a backward LSTM. This algorithm utilizes two unrelated LSTMs to perform data prediction in both forward and backward directions, and it combines the forward and reverse input sequences at the network output layer to obtain the final output value [24–26].
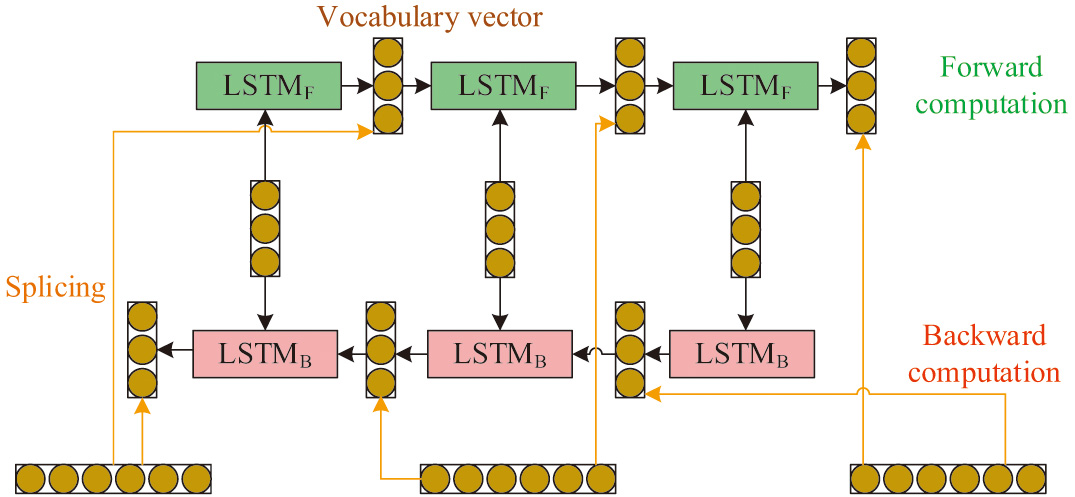
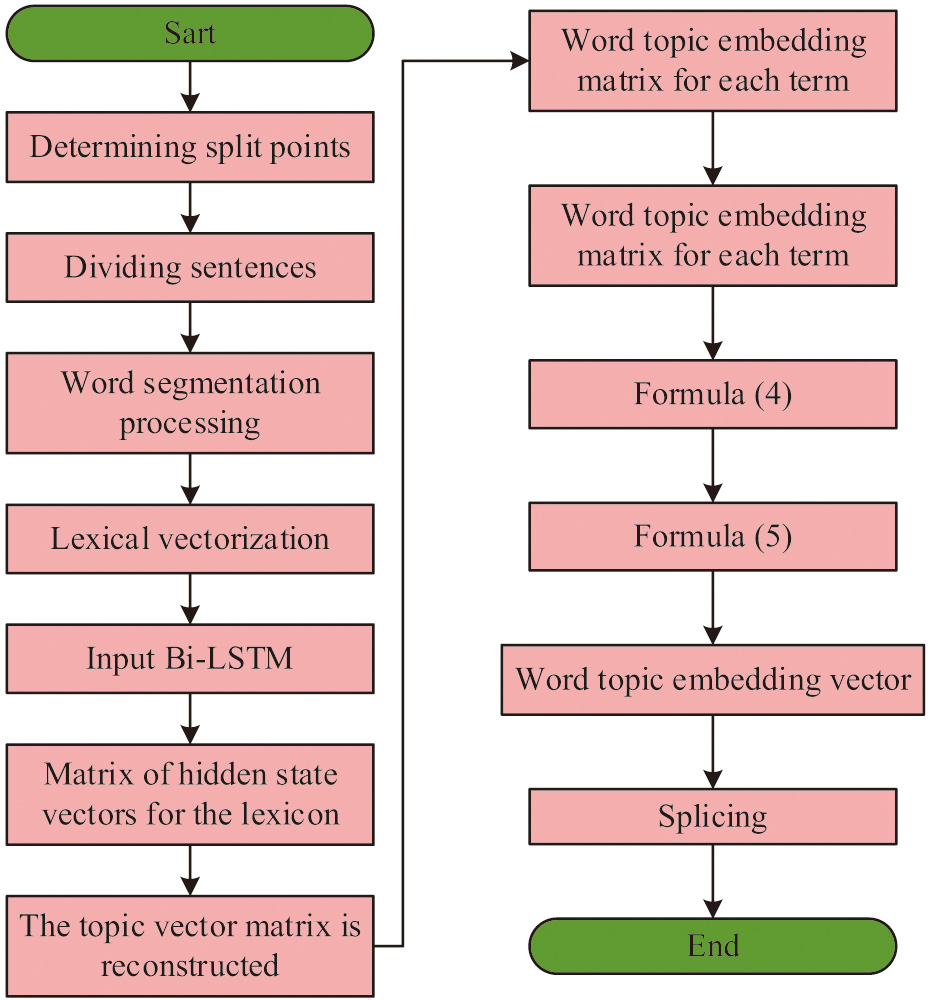 Fig. 5. Sentence sequence processing.
Fig. 5. Sentence sequence processing.
When using Bi-LSTM to obtain matrix , equation (2) is the forward hidden state of the vocabulary calculated by the network.
In equation (2), represents the hidden semantic information vector of the vocabulary, representing all information centered around the vocabulary. represents the forward LSTM unit. is the -th vocabulary. Equation (3) represents the backward hidden state of vocabulary.
In equation (3), represents the backward LSTM unit. The final output is . Then, the relationship between the topic information vector and the hidden state vector for each word can be obtained in equation (4).
Then, the topic feature vector of vocabulary is calculated in equation (5).
In equation (5), represents the low-dimensional topic embedding. Then, and are concatenated to obtain a representation vector that integrates topic information and vocabulary level semantics, which is calculated in equation (6).
B.SENTENCE SEQUENCE PROCESSING BASED ON DOUBLE-LAYER ATTENTION MECHANISM
In the text, emotions can be expressed through the selection of words, the use of tone, sentence structure, and modifiers. Positive emotions may include words such as “like,” “happy,” and “beautiful,” while negative emotions may include words such as “sad,” “angry,” and “painful.” Traditional sentiment analysis methods often convert all the text in the sample set into word sequences and then train the entire word sequence as a sample. This processing method ignores an important component of the discourse: sentence. Its implicit information cannot be ignored [27]. In response to this issue, this study intends to adopt a hierarchical sequence pattern combined with attention mechanism, using text as units by sentence and inputting it into a neural network for learning. Attention mechanisms are adopted at the levels of words and sentences, assigning different weights to words and sentences. Word-level topic information and sequence-level attention mechanisms are combined with LDA topic model and Bi-LSTM. At the lexical level, potential thematic information is introduced into the semantic representation at the lexical level to improve the effectiveness of lexical representation and apply it to multidimensional sentiment classification.
The steps for sentence sequence processing are shown in Figure 5. First, the input document is divided into sentence sequences using punctuation marks as segmentation points. Then, word segmentation is performed, and sentence’s all vocabularies are represented as word vectors using Word2vec. Sentence’s word vectors are input into Bi-LSTM to get the hiding state vector matrix of vocabulary. Then, for each word in each sentence, the topic vector matrix T is reconstructed to obtain the word topic embedding matrix for each word in each sentence. Afterward, the word topic embedding vector is obtained by repeating equations (4) and (5). The concatenation of and word hidden state vectors results in the -th vocabulary’s word-level semantic vector in the -th sentence that integrates topic information.
The organized document is represented by equation (7).
In equation (7), is the maximum number of sentences. Each sentence is segmented to remove useless stop words. The sentence sequence is further organized into a word sequence of equation (8).
However, not every word has equal importance in representing the sentence’s meaning. Therefore, a sequence-level attention mechanism is used afterward to further integrate text semantics into the sequence dimension, thereby constructing text sentiment representation. Firstly, the sentence is expressed as a vector , which is represented by equation (9).
In equation (9), is the contribution weight of a vocabulary to the corresponding sentence, which is calculated in equation (10).
In equation (10), is the parameter that the model needs to learn. is a hidden vector representation of obtained using a single-layer feed-forward network, calculated in equation (11).
In equation (11), is the parameter that needs to be learned. Similarly, for documents, not every sentence contributes equally to the representation of the document’s meaning. Sentence sequence representation is integrated into text representation by using attention mechanism, and document’s vector representation is finally obtained through equation (12).
In equation (12), represents the contribution of a single sentence in the entire document, calculated in equation (13).
In equation (13), is the learning parameter of the model. is a hidden representation obtained from a sentence sequence through a single-layer feed-forward network, calculated in equation (14).
In equation (14), and are learning parameters. The sentiment classifier uses the document sentiment semantic vector to derive the sentiment label , and then maps it to a probabilistic form using the Sigmoid function. The training of this research model adopts an end-to-end backpropagation training method, with the objective function being the cross-entropy cost function. Assuming as the known classifying category and as the predicted one, it aims to make the cross-entropy of and minimized, as displayed in equation (15).
Based on the above research, this study constructs TB-LSTM in Fig. 6. It has four parts: LDA, classifier, sequence-level dual layer attention mechanism, and word-level topic information. Based on multi-level features of text, this model improves the expression efficiency of vocabulary level by integrating topic information extracted by LDA [28]. By introducing attention mechanisms, deep mining at the vocabulary and sequence levels can be implemented, improving the recognition accuracy and generalization ability of the model. Based on a text dictionary, LDA mines topics and analyzes the implicit topics to obtain a potential topic vector matrix. On this basis, the thematic information is transmitted to the lexical level thematic information attention mechanism to expand the expression at the lexical level. Then, the text is structured and transformed into a word sequence. Relying on the Word2vec software, the word sequence is transformed into a word vector matrix, which is then introduced into Bi-LSTM to obtain an implicit representation matrix of the word. Then, under the attention mechanism of topic information, semantic information expression at the word level is obtained based on the association between topic information and implicit representations. Finally, this attention mechanism at the word level is introduced into topic information sentence’s semantic representation, forming a semantic representation at the semantic level. On this basis, a sentiment classifier is used to infer sentiment labels for the text.
When analyzing the emotion of English text sentences, the same emotion word may express different emotional tendencies in different contexts, that is, there exists the problem of emotion ambiguity of emotion words in different sentences. Therefore, the formula (16) is designed to calculate the contribution value of each word to the affective tendency of the sentence, which is represented by the score value , whose value range is [0,1].
Since is related to the context of the target word, context vector is introduced, and is uniformly initialized during the training process. At last, weighted sum of and is used to obtain a new feature representing , which is the final vector of the attention layer. The calculation formula is shown as equation (17).
For example, the word “short” in the sentence “That battery has a very short life.” expresses the writer’s negative emotion toward “That battery.” However, the sentence “Customer service solved the problem in a very short time.” expresses the author’s positive emotion toward “Customer service.” According to the calculation result of equation (17), the final output feature vector contains the emotional feature information of the word and the calculated weight, which is used to judge the importance of the word “short.”
IV.EXPERIMENTAL RESULTS ANALYSIS OF SENTIMENT ANALYSIS MODEL
In order to verify the effectiveness of the designed sentiment analysis model, this study first analyzes the training results to determine its feasibility initially. Then, different datasets are introduced for model application testing to assess its specific application effect in English translation sentiment analysis.
A.EXPERIMENTAL ENVIRONMENT SETTING
The development and construction of the models require an environment that can support the completion of experiments. Table I shows the experimental and development environments for this experiment.
Table I. Experimental environments and development environments
| / | Project name | Configure |
|---|---|---|
| Experimental environment | CPU | Intel Core i5 |
| OS | Windows 10 | |
| JRE | Python3.6.2 | |
| Programming tools | Pycharm5 | |
| RAM | 8GB | |
| Exploitation environment | OS | Windows 10 |
| Programming tools | Pycharm5 | |
| Front-end frame | Vue | |
| Integrated development environment | IntelliJ IDEA | |
| Open source framework | Spring Boot | |
| Database | MySQL |
Before the experiment began, text preprocessing operations were performed on all input documents, including text segmentation, data cleaning, and removing stop words. Because the number of topics in the LDA topic model has a crucial impact on the proposed model, the first step is to conduct parameter validation experiments. is set to 25, 30, and 35, respectively. The performance of the model under various indicators is observed to select the optimal parameter value. Then a comparative experiment is conducted to compare the research model with the methods in references [29–31]. The evaluation indicators are Precision (P), Recall (R), and F1-score.
Dataset 1 selects IMDB English movie reviews, and dataset 2 selected CCF-BDCI Chinese news. IMDB is a two-dimensional dataset that includes both positive and negative emotions. After filtering, 24000 compliant label data were obtained, including 13000 negative evaluations and 12000 positive evaluations. 20000 pieces were used as training data, and 4000 pieces were used as testing data. CCF-BDCI contained a total of 5000 eligible label data, and its emotional dimension was three-dimensional, including positive, neutral, and negative emotions. Among them, there were 2300 negative evaluations, 2000 positive evaluations, and 700 neutral evaluations. 4000 pieces were used as training data, and 1000 pieces were used as testing data. Dataset 3 was selected from the twelve-dimensional Twitter Weibo English on GitHub, which contains 4000 text data with twelve emotional tags. 3000 were trained and 1000 were tested. Dataset 4 selects a seven-dimensional self-built dataset from Sina Weibo, which contains 8000 text data with seven emotional labels. 5000 were trained and another 3000 were tested. Table II shows the training parameters of the research model.
| The parameter name | Numerical value |
|---|---|
| Learning rate | 0.001 |
| Iterations | 300 |
| (Dataset 1 IMDB) | 30 |
| (Dataset 2 CCF-BDCI) | 20 |
| (Dataset 3 Twitter Weibo) | 10 |
| (Dataset 4 self-built) | 5 |
| Text sequence length (Chinese data set) | 300 |
| Text sequence length (English data set) | 100 |
| Word embedding dimension | 300 |
| Embedded dimension | 50 |
| dimension | 100 |
| 200 | |
| Dropout ratio | 50% |
| dimension | 200 |
The ultimate research objective is to apply sentiment analysis to English translation. Therefore, sentiment analysis technology is embedded into translation software to combine the emotional labels output by the model with the semantic understanding module of the translation software to better handle contextual emotional expressions. The sentiment analysis module can use natural language processing techniques to identify information such as emotional polarity (positive, negative, or neutral) and emotional intensity in the text. The translation software is prioritized to process key emotional information. Based on these emotional analysis results, the key emotional information in the original text is determined and made the focus of the translation task. The translation software selected is translator v6.2.620 developed by Google. The accuracy of the evaluation indicators for translation results is selected.
B.MODEL TRAINING RESULTS
Figure 7 shows the training results of parameter . When , the F1-score, P, and R of the research model were all the highest. Therefore, topic selection can affect the effectiveness of sentiment classification directly. This experiment selected 20 topics to construct a model to achieve the best performance.
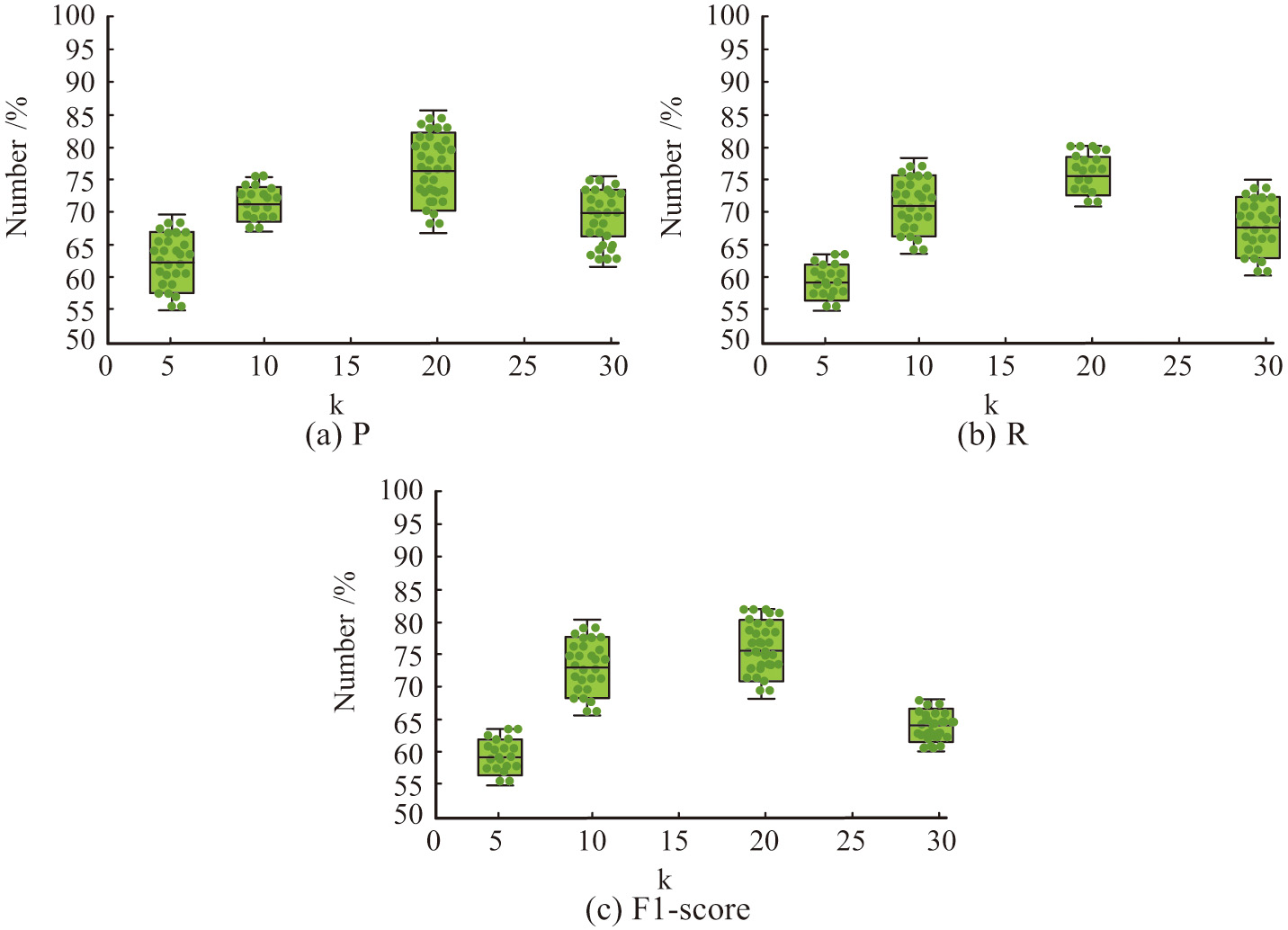 Fig. 7. Training results of the parametersk.
Fig. 7. Training results of the parametersk.
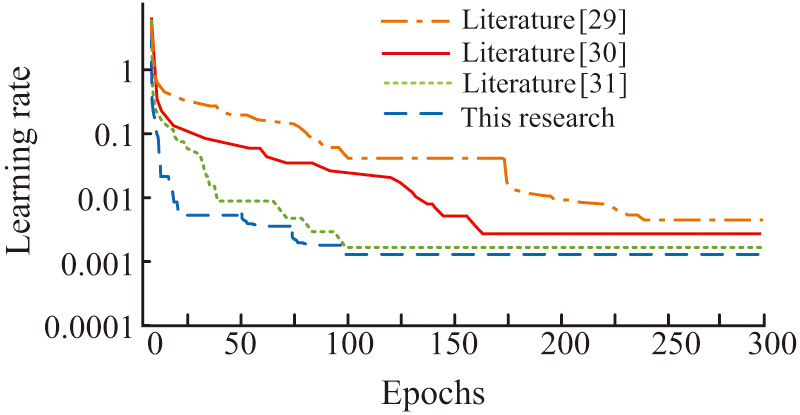
Figure 8 shows the training results of each model. The research model could converge quickly, reaching the convergence state in about 100 iterations, and achieving the expected accuracy. The model in reference [29] had the slowest convergence speed, reaching convergence slowly after 250 iterations. The model in reference [30] converged after 160 iterations. The convergence speed of the model in reference [31] was similar to that of the research model, but it did not achieve the expected accuracy. Relatively speaking, the training performance of research models was better.
C.MODEL TEST RESULTS
Figure 9 shows the classification results of each model on the four datasets. The P, R, and F1-score of the research model on dataset 1 were 0.73, 0.65, and 0.69, respectively. Its P, R, and F1-score on dataset 2 were 0.63, 0.72, and 0.7, respectively. Its P, R, and F1-score on dataset 3 were 0.64, 0.6, and 0.63, respectively. Its P, R, and F1-score on dataset 4 were 0.58, 0.65, and 0.61, respectively. Compared with other models, the research model had the highest values for all indicators, proving its best classification performance.
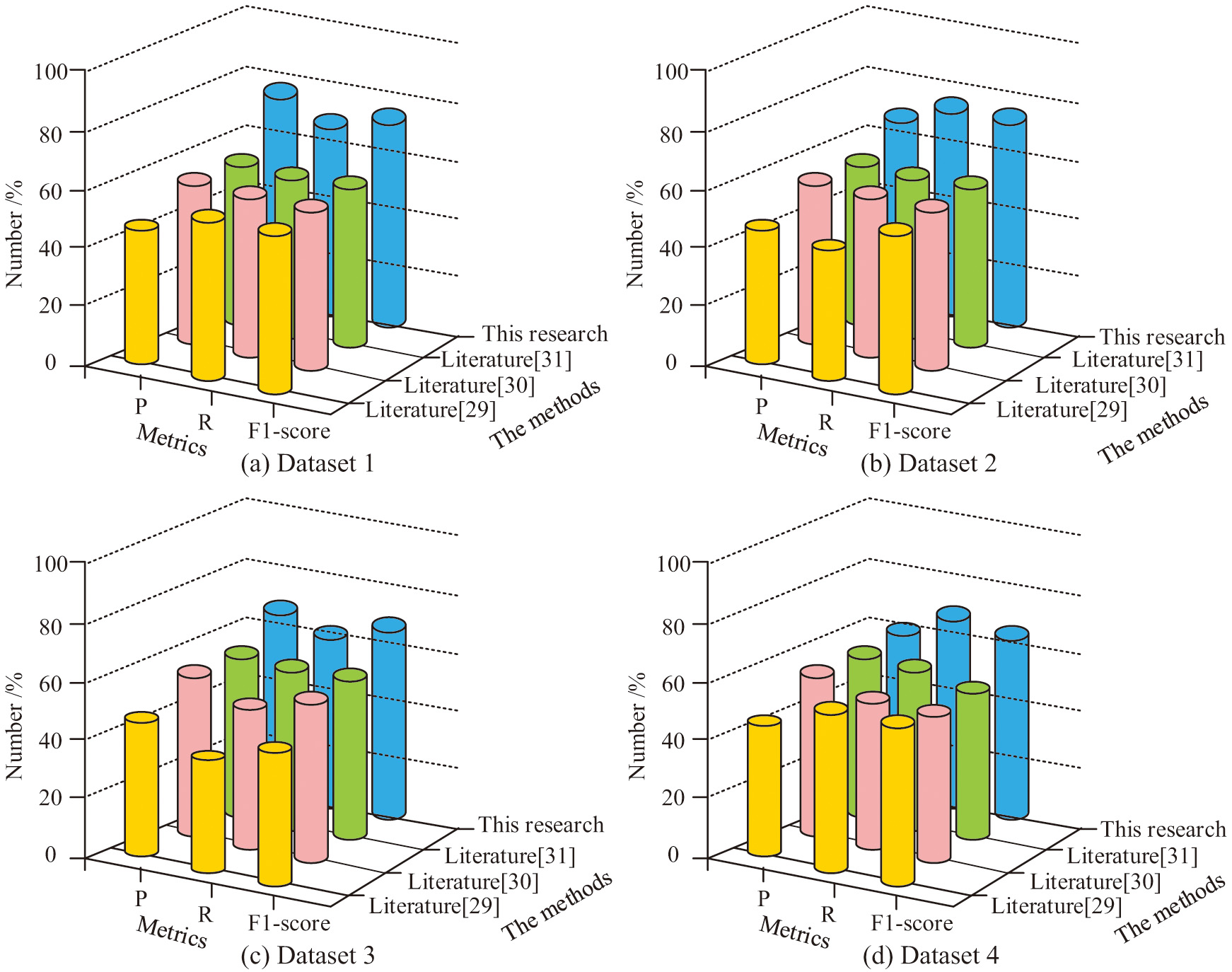 Fig. 9. Classification results for each model on the four datasets.
Fig. 9. Classification results for each model on the four datasets.
Figure 10 shows the classification of the research model in different dimensions. Labels 1–12 in Fig. 10(c) represent 12 emotions, including sadness, excitement, worry, surprise, disgust, happiness, deep love, consideration, boredom, anger, emptiness, and neutrality. Labels 1–7 in Fig. 10(d) represent seven emotions: joy, anger, sadness, fear, love, evil, and shock. The research model had the best classification performance on the two-dimensional text data and the worst classification performance on the twelve-dimensional text dataset. The increase in emotional dimensions increased the difficulties in emotion classification. However, the seven-dimensional sentiment classification still maintained good classification results, and the misclassifications were not significantly different from the three-dimensional classification results.
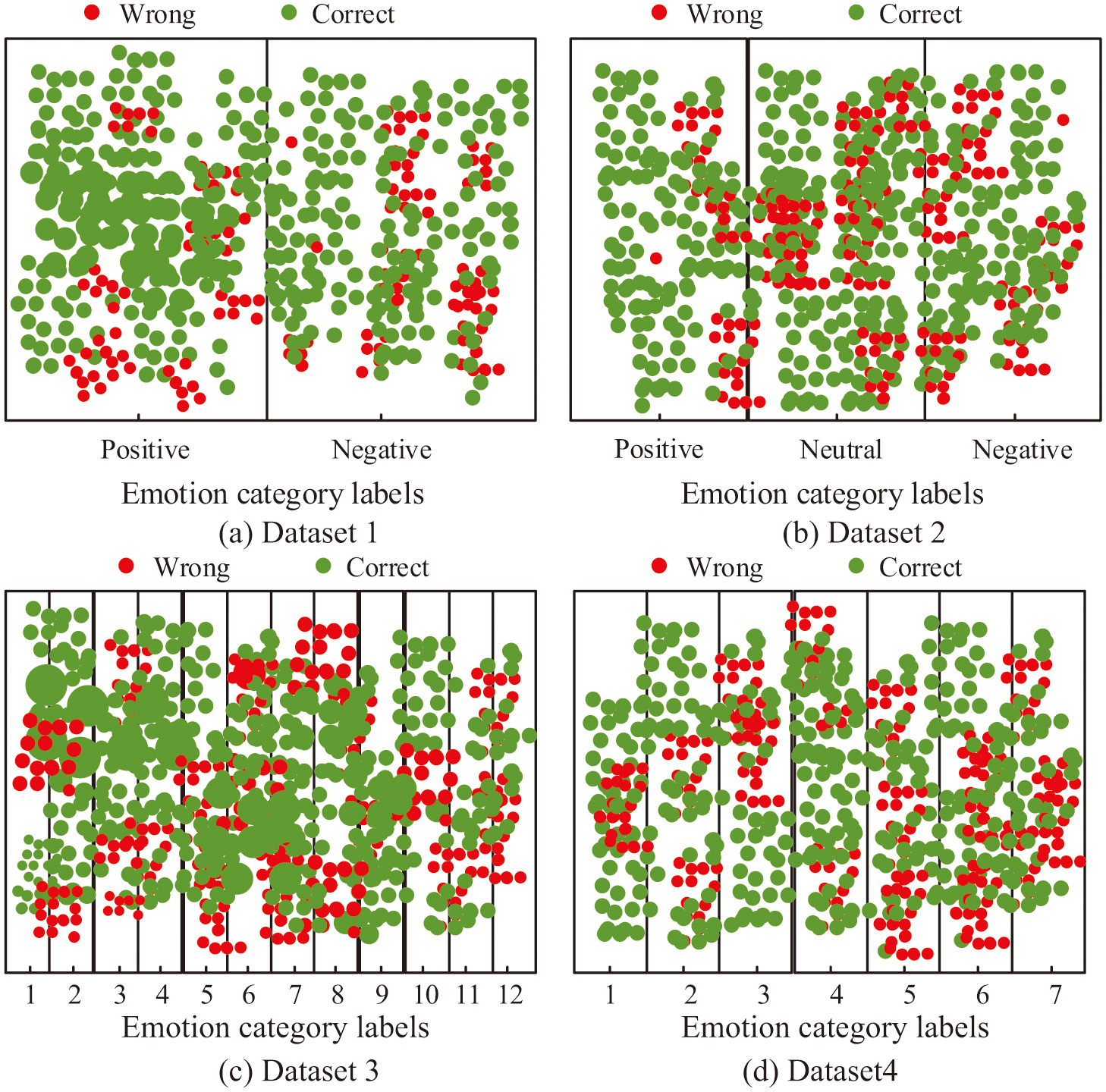 Fig. 10. Classification of the model in this study under different dimensions.
Fig. 10. Classification of the model in this study under different dimensions.
Each dataset is translated and compared with references [32–34]. Figure 11 shows the translation accuracy of the embedded model. From the figure, the translation accuracy of the research model for datasets 1 and 2 was around 0.85, while the translation accuracy of datasets 3 and 4 was relatively low, which were 0.78 and 0.8 respectively. However, compared with the other three models, the translation accuracy of the proposed model was optimal in most cases. On the whole, the translation accuracy of the proposed model is relatively stable and has little fluctuation.
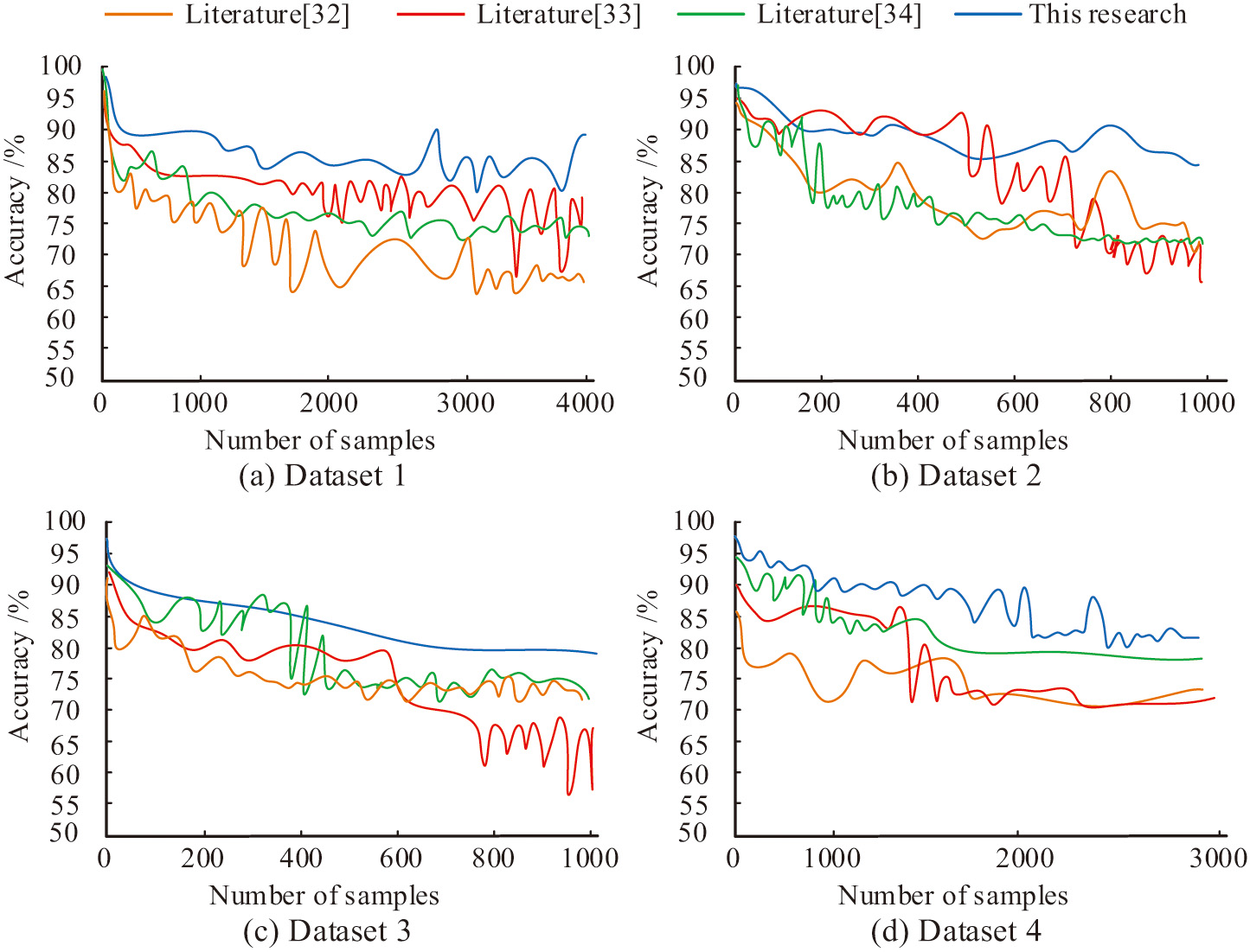
V.CONCLUSION
Emotion refers to the subjective emotional experience and response that humans have toward various events, or situations. It is an important component of human psychological activity, usually involving emotions, preferences, emotional tendencies, and other aspects. To improve the accuracy of sentiment analysis and better grasp text sentiment in machine translation, a two-layer attention mechanism sentiment classification model based on topic information was designed in this study. These experiments confirmed that the P, R, and F1-score of the research model on IMDB were 0.73, 0.65, and 0.69, respectively. Its P, R, and F1-score on CCF-BDCI 2 were 0.63, 0.72, and 0.7, respectively. Its P, R, and F1-score on Twitter Weibo were 0.64, 0.6, and 0.63, respectively. Its P, R, and F1-score on Self-built dataset were 0.58, 0.65, and 0.61, respectively. Compared with other models, the research model had the highest values for all indicators, confirming its best classification performance. As the emotional dimension increased, the accuracy of sentiment classification in research models would decrease but still be higher. The translation accuracy of this embedded research model in the translation system for IMDB and CCF-BDCI was around 0.85, with the lowest accuracy of 0.78 in Twitter Weibo and 0.8 in Self-built dataset. Compared with other methods, the research model had the greatest improvement in translation accuracy. Therefore, its sentiment classification performance was the best, providing new ideas and methods for the development of crosslinguistic sentiment analysis. The multidimensional sentiment classification performance of the research model was better than other models, but there was still room for improvement. Future research will focus on improving the performance of multidimensional sentiment classification models.