I.INTRODUCTION
Cancer is a life-threatening disease with potentially severe consequences. Among the most prevalent types of cancer worldwide, lung cancer remains a leading cause of cancer-related deaths in both developed and developing countries. Non–Small Cell Lung Cancer (NSCLC) accounts for the majority of these cases, with a poor five-year survival rate of only 18%. Despite significant advancements in medical technology that have improved overall cancer survival rates, progress in lung cancer treatment remains slow. This is primarily due to most cases being diagnosed at a late stage. The spread of cancer cells from the lungs to the lymph nodes and eventually into the bloodstream, known as metastasis, plays a critical role in lung cancer progression [1]. Cancer cells typically migrate toward the mediastinum due to natural lymphatic flow. Early detection is crucial in preventing metastasis from spreading to other organs. Regular radiographic follow-ups are essential for monitoring therapeutic responses and tracking changes in tumor characteristics over time.
The role of the primary tumor in lung cancer is similar to that in breast cancer, influencing staging, treatment options, and patient outcomes. Accurate lymph node examination is essential for proper staging and prognosis determination. Traditionally, pathologists have relied on manually reviewing glass slides under microscopes, a process that is both time-consuming and labor-intensive. However, advancements in digital pathology have transformed this practice through slide scanning technology, enabling the digitization of classical pathology. This shift allows for computer-assisted image analysis, reducing manual effort and improving diagnostic efficiency.
Deep learning (DL) approaches, particularly Convolutional Neural Networks (CNNs) [2], such as VGG-19 [8,9], have shown great potential in medical disease diagnosis, including pathology. CNNs have been successfully employed to detect tumor cells across various types of cancer. Accurate assessment of lymph nodes is crucial for classifying cancer and determining the most appropriate therapeutic interventions. Recent studies have demonstrated that histopathological images [3] serve as reliable predictors of therapeutic biomarkers. However, manual screening of multiple slides remains cumbersome and prone to human error. AI-driven solutions have exhibited superior efficiency in detecting micro-metastases compared to pathologists working under high workloads, offering promising advancements in cancer diagnostics.
The workflow of the proposed methodology as follows
- •Introducing the Unet architectures with Convolutional Block Attention Module (CBAM) attention mechanism. The CBAM which consists of two modules channel attention(CA) and spatial attention (SA).
- •In the CA module, global average pooling is followed by two fully connected layer for feature extraction.
- •The SA module generates spatial attention maps by processing feature maps through convolutional layers.
- •Combine attention maps with original feature maps to generate refined representations.
- •Evaluate and compare the proposed model’s performance against other models.
The article is structured as follows: Section II reviews related works, while Section III describes the dataset used for training the proposed model and also discusses various methodologies, including VGG, ResNet, and EfficientNet. Section IV introduces the proposed Unet architecture with CBAM attention. Section V presents experimental results and comparative analysis. Finally, the article concludes with Section VI.
II.RELATED WORK
Lung cancer, characterized by the uncontrolled proliferation of malignant cells within lung tissues, poses a significant global health challenge, contributing to rising mortality rates. While complete eradication remains unattainable, efforts to mitigate its impact are crucial [1,7]. The incidence of lung cancer is strongly correlated with persistent smoking habits. Various classification methodologies, including machine learning (ML) models, have been explored to improve lung cancer diagnosis and treatment. Younis et al. [5] proposed preprocessing strategies using Unet and ResNet algorithms to emphasize lung regions. Extracted features were classified using methods like AdaBoost and Random Forest, and ensemble predictions were employed to estimate the likelihood of cancer presence in CT scans. In another study, Shin et al. [6] utilized deep learning methodologies to analyze the characteristics of cell exosomes, achieving an impressive 95% classification accuracy. Their deep learning algorithm revealed a high similarity between plasma exosomes from patients and extracellular vesicles from lung cancer cells, suggesting potential diagnostic applications. Another study explored the use of clinical factors and radiomic markers to predict lung ADC subtypes using LIFEx software. Additionally, a deep learning network incorporating tumor cell and metastatic staging systems was developed to estimate survival rates and provide personalized therapy recommendations through a user-friendly interface. Furthermore, abnormal lung detection techniques, leveraging segmentation-based ML approaches, have significantly improved performance, particularly when employing Support Vector Machines (SVMs). Ensemble ML models have demonstrated strong predictive power, with performance metrics such as an RMSE of 0.64, recall of 0.97, and an F1-score of 0.96. Recent literature also highlights the effectiveness of ensemble models, including stacking approaches [10], which utilize different embedding techniques for feature extraction.
Medical image segmentation has seen significant advancements with deep learning models and ensemble techniques, particularly in disease detection and classification. Various Unet-based architectures, CNNs, and hybrid networks have been developed to tackle challenges in medical image analysis, including precise tumor detection, disease segmentation, and feature extraction. Meng et al. [12] introduced AFC-Unet, a CNN-transformer model incorporating full-scale attention mechanisms to enhance segmentation accuracy. This model effectively integrates convolutional and transformer components to capture both local and global image features. Similarly, Wan et al. [13] proposed UMF-Net, a multi-branch Unet architecture designed for colon polyp segmentation, employing feature fusion techniques to improve performance by combining features from multiple scales. These approaches emphasize the importance of attention mechanisms and feature fusion in addressing complex medical segmentation tasks, ultimately improving accuracy in detecting and segmenting abnormalities.
Yaohong Suo et al. [11] developed a novel approach for diabetic retinopathy (DR) classification using two modules: the Full Convolution Spatial Attention Module (FCSAM) and CS-ResNet. Additionally, they introduced an image enhancement algorithm to improve image quality, effectively reducing overfitting. Their system achieved an impressive accuracy of 98.1%. Wan et al. [13] also proposed a segmentation-based Unet architecture for polyp segmentation, incorporating multi-fusion techniques to combine attention-based features across different scales. Similarly, Hussain et al. [14] introduced the MAGRes-Unet model, which integrates multiple attention mechanisms with residual connections. This approach employs diverse activation functions and optimizers to enhance feature extraction. Ortega-Ruíz et al. [15] developed DRD-Net for breast cancer segmentation, incorporating dilation, residual, and dense connections to refine imaging features. Meanwhile, Iriawan et al. [16] introduced YOLO-Unet for brain tumor detection, combining the YOLO detection framework with Unet to improve segmentation accuracy in localized tumor regions. This architecture effectively addresses challenges in tumor localization within MRI scans, demonstrating the advantages of integrating object detection with segmentation in medical imaging.
Li et al. [17] contributed to deep-space rock image analysis using the Diamond-Unet, which combines global and local feature extraction with CNN-based cross-fusion paths. Wang et al. [18] implemented attention-based techniques in the Attention-Dual Unet, designed for fusing infrared and visible images, with potential applications in both medical and industrial domains. AlArfaj et al. [19] developed a segmentation-based model for detecting pepper bell leaf diseases, employing a transfer learning mechanism with a Unet-based architecture. Their approach was compared with other transfer learning models, such as InceptionV3, demonstrating enhanced performance. Abuhayi, Bezabh, and Ayalew et al. [20] introduced INVGG, an involution-based VGG network for lumbar disease classification, while Rehman and Gruhn et al. [21] designed an adaptive VGG16-based CNN for knee osteoarthritis stage detection. This model integrated fine-tuned pre-trained VGG19 and CNN features to improve classification performance. Similarly, Sahoo et al. [22] developed an enhanced VGG-19 model to optimize feature pooling, improving the detection of dynamic objects in complex video scenes. This approach is beneficial for medical and non-medical applications requiring high-precision detection in intricate environments.
In lung cancer research, Ardila et al. [24] demonstrated the effectiveness of a 3D CNN-based approach for lung cancer screening using low-dose CT scans, setting a benchmark for automated screening in oncology. Kareem et al. [25] explored Support Vector Machines (SVMs) for lung cancer detection, highlighting the relevance of non-deep learning approaches in image-based diagnostics. Rajasekar et al. [23,26] applied deep learning techniques to predict lung cancer using CT scans and histopathological images, emphasizing the benefits of multi-modal data integration. Comparative studies by Radhika et al. [27] and Pradhan and Chawla et al. [28] have analyzed various machine learning algorithms for lung cancer detection, providing insights into the evolution from traditional ML techniques to advanced deep learning architectures in medical diagnostics. These studies underscore the shift towards sophisticated neural network-based solutions, significantly improving diagnostic accuracy and efficiency in lung cancer detection.
III.DATASET AND METHODOLOGY
This section presents the dataset used in this study and the methodology employed. It includes the use of pre-trained models such as VGG-16, VGG-19, ResNet-50, ResNet-101, and EfficientNet, all trained on the dataset. The study leverages these models to analyze their effectiveness in achieving the desired outcomes. The dataset serves as the foundation for training and evaluating these architectures, ensuring a comprehensive comparison of their performance. By utilizing well-established deep learning models, this approach enhances the reliability of the results. The methodology focuses on optimizing model performance while maintaining consistency across different architectures for a thorough evaluation.
A.DATASET DESCRIPTION
The Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases (IQ-OTH/NCCD) lung cancer dataset was collected in the above-mentioned specialist hospitals over a period of three months in fall 2019. It includes CT scans of patients diagnosed with lung cancer in different stages, as well as healthy subjects. IQ-OTH/NCCD slides were marked by oncologists and radiologists in these two centers. This dataset features CT scans from patients, as well as scans from healthy individuals. In total, the dataset comprises 1,097 CT slices from 110 cases, divided into three categories: normal, benign, and malignant. Specifically, 561 scans are classified as malignant, 120 as benign, and 416 as normal. The dataset can be accessed through the dataset [4], and sample images for each category are provided in Fig. 1.

B.METHODOLOGY (PRE-TRAINED MODELS)
In this section, we conduct experiments using various deep learning architectures, including VGG, ResNet, and EfficientNet. These models are selected based on existing literature to facilitate a comprehensive comparison with the proposed method. VGG is a well-established deep CNN architecture known for its effectiveness in various computer vision tasks, particularly image classification [17,18]. The VGG-16 model consists of multiple convolutional layers followed by fully connected layers, forming a structured design. It comprises five convolutional blocks, each containing multiple convolutional layers, followed by max-pooling layers, which optimize feature extraction and representation. ResNet-50, originally designed for large-scale image classification, is adapted for lung cancer classification in this study [19]. The key innovation in ResNet is the introduction of residual blocks, which help mitigate the vanishing gradient problem and facilitate efficient training of deep networks. Mathematically, a residual block can be defined as follows: given an input X[l], the transformation within the block can be expressed as X[l+1] = X[l] + F (X[l], W[l]), where F represents the residual function, and W[l] denotes the learned weights. The fully connected layers at the end of the ResNet-50 model further refine the extracted features for accurate classification.
EfficientNet is designed to achieve high accuracy while maintaining computational efficiency [29–31]. It addresses the challenge of network scaling by balancing three key dimensions: depth, width, and resolution. Deeper networks capture more complex features but require more computation, while wider networks process more information in parallel but demand additional memory. Higher input resolution provides finer details but increases computational cost. EfficientNet incorporates MBConv (Mobile Inverted Bottleneck Convolution) layers, which enhance feature representation and improve model performance. This architectural design is particularly beneficial for medical applications, such as lung cancer detection, where achieving high accuracy with optimized computational resources is crucial.
IV.PROPOSED METHODOLOGY
The proposed model as shown in Fig. 2, takes resized images of input images of size 3 × 224 × 224, which means it’s designed for RGB images with a 224 × 224 pixel resolution. The network is structured with multiple stages of convolutional layers (CL), each augmented with CBAM to enhance feature extraction by directing attention to important areas. Each layer is followed by normalization and sigmoid activation function, which helps improve the network’s learning capabilities and overall stability.
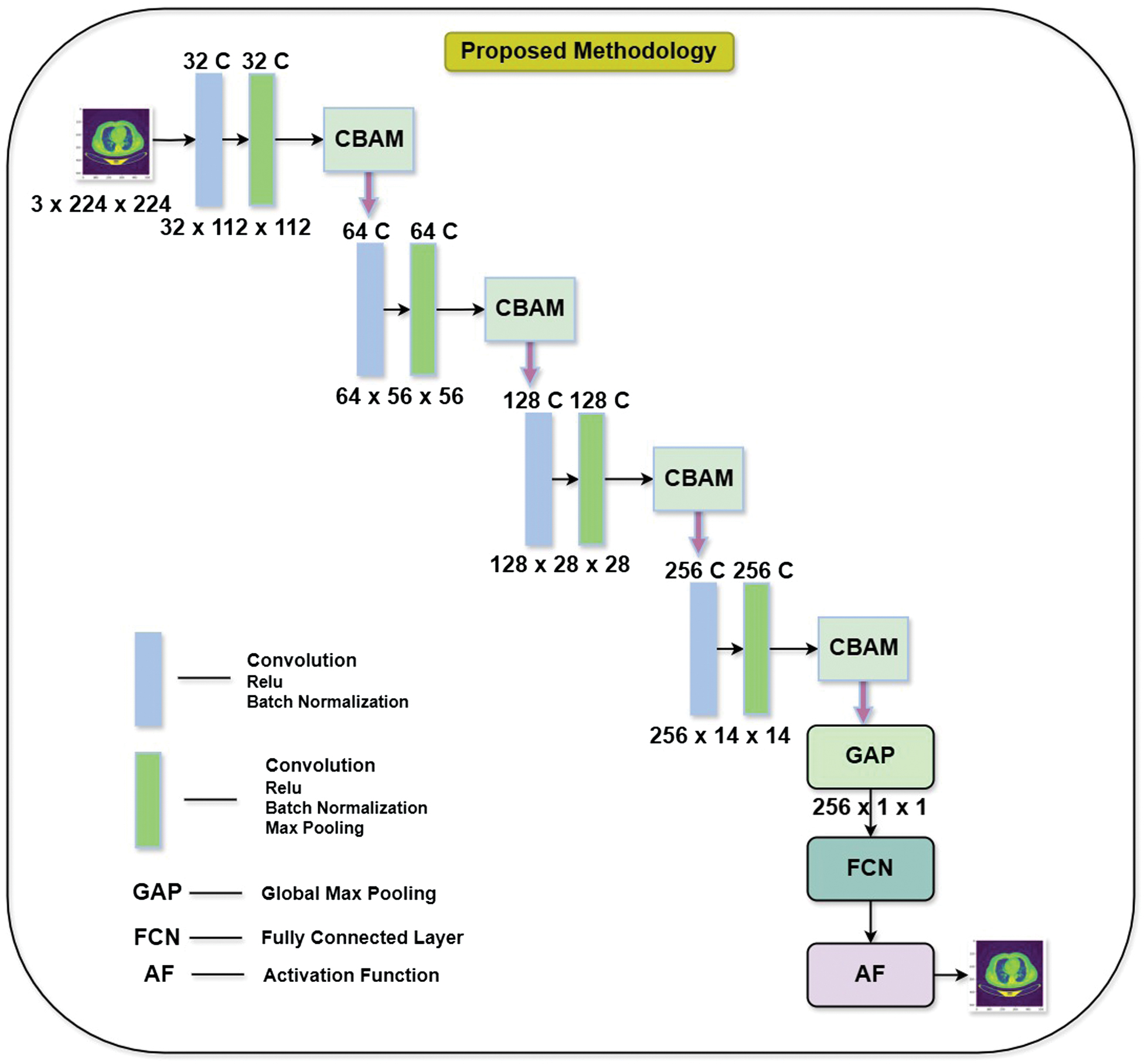 Fig. 2. Unet with CBAM architecture.
Fig. 2. Unet with CBAM architecture.
The input consists of an RGB image of size 224 × 224 pixels. A CL with 32 filters is applied, followed by ReLU activation and batch normalization. Output Feature Map reduces the image dimensions to 32 × 112 × 112, indicating a downsampling operation, likely from stride or pooling. The network progresses through multiple blocks that involve sequential convolutions, with CBAM modules incorporated after specific layers to refine feature representations by emphasizing important information.
The proposed methodology extracts the feature from the various stages such as in Unet based model. Each stage in the model employs the feature extracted and combines them with the attention mechanism. Here CBAM based attention is used at every stage, which consists of attention at two levels. At the first level, it is of channel attention, and the next level is of the spatial attention throughout at every stage of the Unet architecture. The architecture also employs efficient downsampling through a combination of convolution and pooling layers, which gradually reduces the spatial dimensions of feature maps while preserving essential hierarchical structures. Additionally, after each convolution step before normalization, helping to stabilize the training process, speed up convergence, and reduce internal covariate.
A.CBAM ATTENTION MECHANISM
Convolutional Block Attention Module (CBAM) is a powerful tool for enhancing the performance of CNNs tasks, including the prediction of lung cancer. CBAM integrates [7] both spatial and channel-wise attention mechanisms to adaptively highlight informative features within the input data. The CBAM module consists of two attention blocks: the CA block and the SA block as shown in Fig. 3.
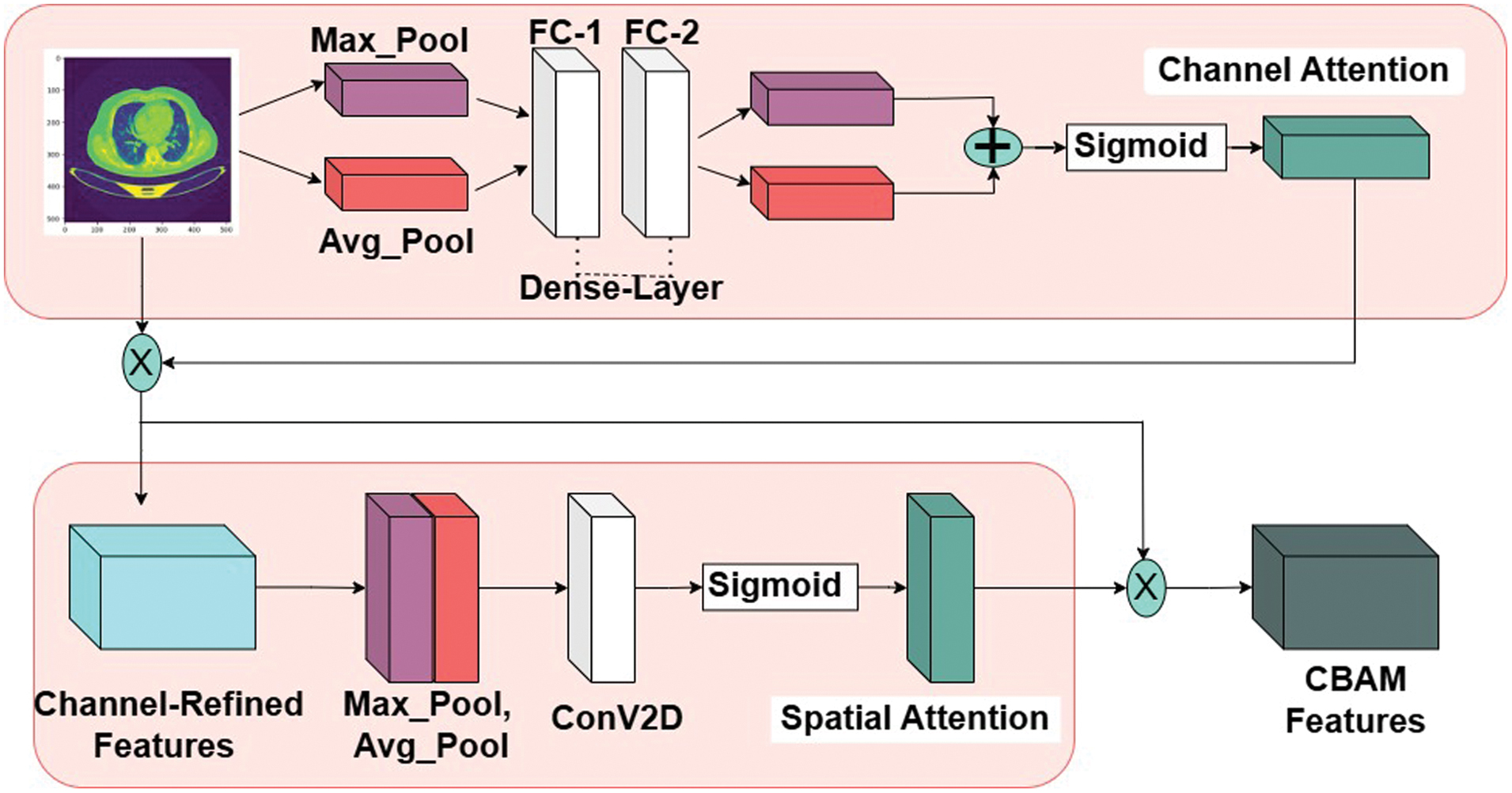 Fig. 3. Convolutional Block Attention module (CBAM) architecture.
Fig. 3. Convolutional Block Attention module (CBAM) architecture.
1.CHANNEL ATTENTION (CA) BLOCK
This block captures the interdependencies between feature channels by calculating channel-wise attention maps. It computes the importance of each feature channel by utilizing global average pooling and max-pooling operations followed by a series of FC layers. Attention weights obtained from the CA block are then applied to each feature map across all spatial locations.
Let X be the feature map of input size C×H×W, where C #channels, H- height, and W-width. In output of the CA block is computed as follows: First, the average and max pooling operations are applied along spatial dimensions to obtain global average and max pooled feature vectors, respectively in equation (1–4):
Here, Wavg and Wmax are the learnable weights of the fully connected layers, and FCavg and FCmax represent the fully connected layers. Finally, the channel-wise attention maps are combined using element-wise addition or multiplication to produce the output feature map as defined in equation (5):
2.SPATIAL ATTENTION (SA) BLOCK
Unlike the CA block, the SA block focuses on capturing spatial dependencies within feature maps. It generates spatial attention maps by considering correlations between neighboring spatial locations. This is achieved through a combination of max pooling and average pooling operations along both spatial dimensions, followed by fully connected layers. The resulting attention weights highlight relevant spatial regions.
By combining the outputs of the CA and SA blocks through element-wise addition or multiplication, the CBAM module produces enhanced feature maps that emphasize both informative channels and spatial regions. Similarly, let X be the input as C×H×W, The output of the SA block is computed as follows: First, the average and max pooling operations are applied along channel dimensions to obtain channel-wise average and max-pooled feature maps, respectively as defined in equation (6–8):
Next, the concatenated feature map is processed through a convolutional layer and then a sigmoid activation function to generate the spatial attention map as defined in equation (9):
Here, Wcon represents the learnable weights of the convolutional layer. Finally, the spatial attention map is applied to the input feature map using element-wise multiplication to produce the output feature map as defined in equation (10):
V.RESULTS AND DISCUSSION
In this Section, the detailed experimental results are explored in the Tables I–V. The dataset with experiments results of VGG-16, VGG-19, ResNet-50 and EfficientNet are explored with hyper parameters such as learning late, epochs and performance metrics. The results of proposed method such Unet with CBAM are perform better than other existing methods.
Table I. Performance of VGG-16 and VGG-19 models
| Model | VGG-16 | VGG-19 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | Learning Rate(L) = 0.0001 | Learning Rate(L) = 0.0001 | ||||||||
| Epochs | 2 | 4 | 6 | 8 | 10 | 2 | 4 | 6 | 8 | 10 |
| 94.26 | 90.22 | 92.48 | 92.40 | 88.48 | 82.40 | 86.40 | 86.20 | |||
| 92.40 | 90.20 | 93.40 | 90.10 | 86.40 | 82.20 | 83.20 | 82.40 | |||
| 92.10 | 89.48 | 90.10 | 90.20 | 86.60 | 87.20 | 82.40 | 92.30 | |||
| 92.25 | 89.84 | 91.75 | 90.15 | 86.50 | 84.70 | 82.80 | 87.35 | |||
Table II. Performance of ResNet-50 and ResNet-101 models
| Model | ResNet-50 | ResNet-101 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | Learning Rate(L) = 0.0001 | Learning Rate(L) = 0.0001 | ||||||||
| Epochs | 2 | 4 | 6 | 8 | 10 | 2 | 4 | 6 | 8 | 10 |
| 86.48 | 84.20 | 80.30 | 85.30 | 86.20 | 84.30 | 84.20 | 82.40 | |||
| 84.50 | 86.80 | 88.40 | 84.40 | 94.40 | 96.60 | 92.20 | 90.50 | |||
| 84.20 | 84.50 | 86.40 | 84.20 | 88.20 | 90.40 | 88.60 | 90.30 | |||
| 84.35 | 85.65 | 87.40 | 84.3 | 91.30 | 93.50 | 90.40 | 90.40 | |||
Table III. Performance of EfficientNet model
| Model | EfficientNet | ||||
|---|---|---|---|---|---|
| Parameter | Learning Rate(L) = 0.0001 | ||||
| Epochs | 2 | 4 | 6 | 8 | 10 |
| 94.60 | 94.50 | 94.40 | 94.60 | ||
| 92.20 | 94.80 | 94.60 | 94.30 | ||
| 94.60 | 92.60 | 92.40 | 93.20 | ||
| 93.40 | 93.70 | 93.50 | 94.25 | ||
Table IV. Performance of proposed method
| Model | Unet with CBAM(Proposed Method) | ||||
|---|---|---|---|---|---|
| Parameter | Learning Rate(L) = 0.0001 | ||||
| Epochs | 2 | 4 | 6 | 8 | 10 |
| 96.40 | 96.20 | 96.20 | 94.80 | ||
| 94.60 | 94.80 | 96.40 | 94.60 | ||
| 92.40 | 95.30 | 94.20 | 95.20 | ||
| 93.50 | 95.50 | 95.30 | 94.50 | ||
Table V. Comparison of various deep learning models with proposed model
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| VGG-16 | 92.80 | 94.60 | 94.80 | 94.70 |
| VGG-19 | 90.40 | 91.20 | 90.40 | 90.80 |
| Res-50 | 88.20 | 88.20 | 88.80 | 88.50 |
| ResNet-101 | 88.40 | 90.20 | 88.40 | 89.30 |
| EfficientNet | 95.20 | 94.80 | 95.30 | 95.50 |
A.COMPARISON STUDY
The comparison of various DL models with the proposed Unet with CBAM model highlights the superior performance of the CBAM approach. VGG-16 and VGG-19 models show strong precision (94.60% and 90.40%, respectively) but have lower recall and F1-scores. ResNet-50 and ResNet-101 demonstrate even lower performance metrics, with ResNet-50 having an accuracy of 88.20% and ResNet-101 slightly better at 88.40%. EfficientNet performs notably well, achieving 95.20% accuracy and high scores in precision, recall, and F1-score (94.80%, 95.30%, and 95.50%, respectively). However, the proposed Unet with CBAM model surpasses all these models with an impressive accuracy, precision, recall and F1-score 96.80%, 96.40%, 96.60%, 96.50% showcasing its effectiveness.
VI.CONCLUSION
In this study, the early detection of lung cancer, a critical aspect of patient diagnosis and treatment, was significantly enhanced by the proposed methodology incorporating Unet with CBAM. By integrating channel and spatial attention modules, the proposed approach effectively addressed the limitations of existing deep learning models, such as VGG-16, VGG-19, Inception V3, and ResNet-50, in recognizing malignant lung cells. The model achieved improved performance by supplying integrated features from each module to a meta-learner, resulting in higher recognition accuracy, precision, sensitivity, F-score, and specificity. These findings demonstrated the potential of CBAM-enhanced deep learning in improving early lung cancer detection and diagnosis, ultimately contributing to better patient outcomes.