I.INTRODUCTION
A.BACKGROUND OF AUTONOMOUS DRIVING
One of the most revolutionary emergences in transportation is autonomous driving. Self-driving cars have come a long way in the last ten years with artificial intelligence (AI), machine learning (ML), and advanced sensing technologies all converging to rapidly improve the development of autonomous vehicles (AVs). AVs are set to transform road safety, efficient traffic management, and urban transportation systems by minimizing human interaction with the vehicle during driving tasks. This technology, at its heart, is the ability of vehicles to sense their environment through multiple sensors via camera, LiDAR, and radar. Floated with the help of #deep_learning, implicit knowledge without automatic machines will take place now that social media can automatically suck ML data from the sensor experience and make the hull fly and process data.
B.IMPORTANCE OF OBJECT DETECTION IN AVs
The reason why object detection is significant to the AV is because it helps the car recognize and classify the items within the environment that he is passing by, such as pedestrians, cyclists, vehicles, traffic signals, and other obstacles. The failure to accurately detect objects can result in the uselessness of an autonomous driving system to model the dynamic nature of the road, which means safety as well. Deep learning techniques based on CNNs have significantly improved object detection model’s accuracy and speed in recent years. Recognizing multiple objects simultaneously and categorizing them in real-time can be a resource-exhaustive task for AVs and remains susceptible to adverse weather, lighting, and increasingly complex driving environments such as dense urban areas and highways. To avoid collisions and safely navigate, the vehicle needs to detect the objects around it efficiently [3].
C.SIGNIFICANCE OF LANE DETECTION FOR AUTONOMOUS NAVIGATION
The field of vision-based autonomy in cars is lane detection which is critical to navigation in the context of self-driving cars. The ability to keep a vehicle in its driving lane is a basic requirement of driving on highways and around town. Previously, classical lane detection techniques were based on edge detection + geometric models, which suffered from sensitivity to road conditions, lighting, and weather. In the field of modern lane detection, however, deep learning models are now regularly used to improve the speed and accuracy of lane tracking, even in difficult conditions. Such systems work with lane detection algorithms that assist lane centering, lane change, and keeping vehicle position over road markings required for semi-autonomous and fully autonomous driving systems [6].
D.RESEARCH MOTIVATION AND PROBLEM STATEMENT
Fundamentally, the motivation of this paper is to enhance the existing lane and object detection systems in AVs. Despite the tremendous advancements, existing models continue to underperform in scenarios with diverse lighting and weather conditions as well as highly dynamic road situations. Occlusions and small object sizes can affect accuracy in object detection models, and lane detection may struggle with faded or blocked markings on the road. The goal of this research is to provide a unified and more sophisticated method for using deep learning to object and lane detection with the hope that it may achieve greater accuracy and real-time performance in difficult situations [12].
E.OBJECTIVES OF THE STUDY
The primary objective of this study is to investigate and implement advanced deep learning models for improving object and lane detection in autonomous driving systems. Specifically, the study aims to:
Enhance the accuracy and robustness of object detection algorithms in varying environmental conditions.
Develop a deep learning-based lane detection system capable of recognizing road markings with high precision, even in adverse conditions.
Evaluate the integration of object and lane detection models to ensure seamless real-time navigation.
Provide insights into the practical application of these algorithms in commercial AV systems [10].
The rest of this paper is structured as follows: Section II reviews existing deep learning-based object and lane detection methods. Section III presents the proposed methodology, detailing dataset selection, model architecture, and integration techniques. Section IV discusses experimental results and performance evaluation. Section V outlines challenges and future research directions, followed by conclusions in Section.
II.LITERATURE REVIEW
A.OVERVIEW OF DEEP LEARNING IN AUTONOMOUS DRIVING
Deep learning has revolutionized the field of autonomous driving by enabling powerful tools for object recognition, scene understanding, and decision-making. This is particularly true for processing massive amounts of visual data from sensors on AVs employing deep learning models, especially CNNs, which have shown remarkable performance. These models allow for the learning of more complex patterns and features in data via images, which empowers AVs to perceive their environment in a more accurate and timely manner than what is achievable through traditional algorithms [4]. Deep learning models offer huge open-source popular models like YOLO (You Only Look Once) or SSD (Single Shot Multibox Detector) object detectors, which due to the fact of running in real-time and with high accuracy, have been adopted as a standard.
B.STATE-OF-THE-ART OBJECT DETECTION ALGORITHMS
Object detection also has progressed significantly through the development of new deep learning models. Models such as YOLO and SSD-X have established state-of-the-art performance for real-time object detection, making them the recommended models for use in autonomous driving scenarios. Its latest version, YOLOv5, features fast detection time and high accuracy [7]. Likewise, SSD is all about balancing speed with the accuracy of detection and is aimed at those applications that require real-time decision-making. While relatively good at this, and much improved over previous models, they struggle with small objects that are only partially visible, typically in some cluttered space. To address these challenges, researchers have been investigating hybrid models and advances in network architecture [9].
C.REVIEW OF LANE DETECTION ALGORITHMS
Traditional lane detection was performed with edge detection and Hough transform-based methods. But these methods were sensitive to the conditions of the road and, for example, typically they failed on non-ideal road conditions like worn road markings or complex lane structures. More recently, convolutional neural network-based (CNN) models have been proposed to overcome these downsides. Models based on CNNs can extract feature maps from images and learn to find lane pixels in a range of environments. Also, recurrent neural networks and spatial CNNs have been introduced to model temporal dependencies to enhance lane detection performance over time [5].
D.EXISTING SOLUTIONS AND THEIR LIMITATIONS
The primary limitations observed in previous studies [8,9] were the inefficiencies in detecting small objects and handling occlusions in dynamic driving conditions. Faster R-CNN provided high accuracy but lacked real-time efficiency, making it unsuitable for on-the-fly object detection in AVs. Similarly, SSD offered speed advantages but suffered from reduced detection accuracy for occluded and smaller objects. Our hybrid approach integrates YOLOv5 with CNN-based lane detection, addressing these issues by leveraging advanced feature extraction and temporal dependencies for both object recognition and lane tracking, thereby improving real-time navigation reliability in diverse conditions.
E.CHALLENGES IN OBJECT AND LANE DETECTION FOR AVs
The primary challenges in object and lane detection for AVs are as follows:
Environmental Variability: AVs must operate in a wide range of environments, including urban, rural, and highway settings, each of which presents unique challenges for object and lane detection.
Real-time Processing: The ability to process data in real-time is crucial for autonomous driving, as any delay in detection could lead to accidents.
Occlusions and Clutter: Objects such as pedestrians, bicycles, and other vehicles can be partially or fully obscured, making detection more difficult.
Lane Marking Variability: Lane markings can vary greatly in appearance due to road conditions, wear, and weather, making consistent detection challenging [6].
F.SUMMARY OF RESEARCH GAPS
Although many research works are very promising in deep learning image processing for object and lane detections, there are still several gaps that need to be filled. For the most part, current models perform poorly when faced with challenging real-world conditions, such as weather, lighting, and road conditions. Moreover, combining object and lane detection into a single entity that works well in real time is still a daunting task. Thus, this study proposed to fill these gaps and to achieve an outperforming dedicated integrated detection system, that can work reliably under various conditions [11].
III.METHODOLOGY
A.KITTI DATASET
While deep learning models such as Faster R-CNN, SSD, and traditional lane detection methods have been widely used, they suffer from inefficiencies in handling occlusions, small objects, and rapid lane changes in real-world autonomous driving conditions. This study proposes an enhanced fusion-based detection system that integrates YOLOv5 for real-time object detection with a CNN-based lane detection model. Unlike existing approaches, our method optimizes feature fusion through adaptive region proposal networks, reducing redundant calculations while improving detection speed and accuracy as in Table II. The core novelty of our work lies in optimizing spatial-temporal feature extraction, reducing false positives, and improving response time under varied environmental conditions. Experimental evaluations confirm that our approach achieves significant accuracy improvements while maintaining real-time performance.
- 1.COCO Dataset (Common Objects in Context): This dataset contains over 330,000 images, with more than 200,000 labeled images used for object detection. It provides a variety of object classes such as pedestrians, vehicles, and traffic signs, as in Fig. 1, all crucial for autonomous driving systems [11] (Link: https://cocodataset.org/#home.)
- 2.TuSimple Lane Detection Dataset: This dataset includes 6,408 video clips and corresponding annotations for lane detection. The dataset is designed for highway driving scenarios, with annotations for multiple lanes per image [15], as in Fig. 2. Also, use the KITTI Dataset to confirm real-driving capabilities in object detection of models in the city domain and ApolloScape Dataset to improve the generalization of the inferred map
Data Preprocessing Steps:
- •Resizing: Images were resized to 416×416 pixels for compatibility with deep learning models.
- •Normalization: Pixel values were normalized to a [0, 1] range to improve the training stability of the neural networks.
- •Data Augmentation: Techniques like random rotation, scaling, and flipping were applied to prevent overfitting and enhance model robustness.
B.DEEP LEARNING MODELS USED FOR OBJECT DETECTION
Two primary models were used for object detection in this study: CNNs and advanced real-time object detectors like YOLO and SSD [1].
1.CNNS
CNNs have been a foundational architecture in deep learning for image-related tasks. A basic CNN architecture comprises convolutional layers for feature extraction, pooling layers for dimensionality reduction, and fully connected layers for classification. In this study, we adopted a variant of the ResNet50 architecture, which is known for its strong feature extraction capability through residual learning [5]. The CNN was trained using the COCO dataset to detect multiple objects in various driving conditions [2].
Algorithm 1: CNN Architecture for Object Detection
Input: Image (416×416)
Layer 1: Convolution (64 filters, 3×3 kernel) + ReLU + MaxPooling (2×2)
Layer 2: Convolution (128 filters, 3×3 kernel) + ReLU + MaxPooling (2×2)
…
Layer N: Fully Connected + Softmax
Output: Probability distribution over object classes
2.YOLO AND SSD
YOLO and SSD are popular real-time object detection models. YOLO processes an entire image in a single forward pass through the network, making it highly efficient for real-time applications. In this study, we employed YOLOv5 due to its speed and accuracy. The SSD model was also integrated for comparative analysis, as it balances speed and detection accuracy by using a multiscale feature map approach [17].
C.LANE DETECTION ALGORITHMS
Lane detection is another crucial aspect of autonomous driving, as it ensures the vehicle stays within the appropriate driving lanes. In this research, we explored both traditional and deep learning-based methods for lane detection.
1.HOUGH TRANSFORM-BASED APPROACHES
The Hough transform is a classical method used to detect lines in an image. For lane detection, this algorithm was applied to detect straight lines representing lane boundaries. The steps include edge detection using the Canny operator, followed by the Hough transform to identify lane markings. This approach is computationally light but struggles with curved lanes and noisy data [25].
Algorithm 2: Hough transform for Lane Detection
Input: Image (grayscale)
Step 1: Edge detection using the Canny algorithm
Step 2: Apply Hough transform to detect lines
Step 3: Overlay detected lines onto the original image
Output: Lane markings (straight lines)
2.DEEP LEARNING-BASED LANE DETECTION
For improved performance in more complex environments, we implemented a CNN-based lane detection model. The spatial CNN architecture allows the model to consider the spatial relationships between lane markings and extract features that are robust to lighting conditions and road curvature. The model was trained using the TuSimple dataset, providing high accuracy in lane detection [30].
D.INTEGRATION OF OBJECT AND LANE DETECTION
The integration process aligns lane detection outputs with object detection bounding boxes in a shared coordinate space, ensuring seamless perception for AVs. The following figure illustrates the pipeline used for combining these modules into a single system capable of real-time perception and decision-making [5].
E.TRAINING AND EVALUATION METRICS
The proposed system optimizes computation efficiency by leveraging parallel processing for object and lane detection. The fusion of detection results reduces redundant bounding box computations, enabling faster inference compared to traditional sequential models. Experimental results indicate that while the proposed model requires approximately 1.3× processing time compared to SSD, it significantly outperforms SSD in accuracy and robustness, particularly in occlusion-heavy environments
- •Precision: Measures the accuracy of positive predictions (True Positives/(True Positives + False Positives)).
- •Recall: Measures the model’s ability to identify all relevant objects (True Positives/(True Positives + False Negatives)).
- •F1-score: Harmonic mean of precision and recall, providing a single performance score.
- •Intersection Over Union (IoU): Evaluates the overlap between the predicted bounding boxes and the ground truth boxes in object detection.
F.EXPERIMENTAL SETUP AND TOOLS
The experimental setup involved using a machine equipped with an NVIDIA RTX 3080 GPU and 64GB of RAM. The models were developed using the TensorFlow and PyTorch frameworks. The training was carried out for 50 epochs with a batch size of 32, and the Adam optimizer was used with a learning rate of 0.001. Data augmentation techniques such as random cropping, rotation, and contrast adjustment were employed to improve the model’s robustness to varying driving conditions [8].
The tools used include the following:
- •TensorFlow and PyTorch: For developing and training deep learning models.
- •OpenCV: For image preprocessing and traditional computer vision techniques like the Hough transform.
- •CUDA: For leveraging GPU resources to accelerate training.
IV.RESULTS AND ANALYSIS
A.PERFORMANCE METRICS FOR OBJECT DETECTION
To evaluate the effectiveness of the object detection models, performance metrics such as precision, recall, F1-score, and IoU were used, as in Table III. These metrics provide insight into the model’s ability to accurately detect and classify objects in real-time driving scenarios.
1.PRECISION, RECALL, AND F1-SCORE
The precision, recall, and F1-score were calculated for the object detection models (YOLOv5 and SSD) as shown in Table IV. These metrics are essential for understanding the balance between detecting all relevant objects (recall) and avoiding false positives (precision) [26].
As observed in Table I, YOLOv5 outperforms SSD in terms of precision, recall, and F1-score, indicating that it has a better balance between detecting true objects and minimizing false positives. The higher F1-score of YOLOv5 reflects its superior overall performance in real-time object detection [23,29].
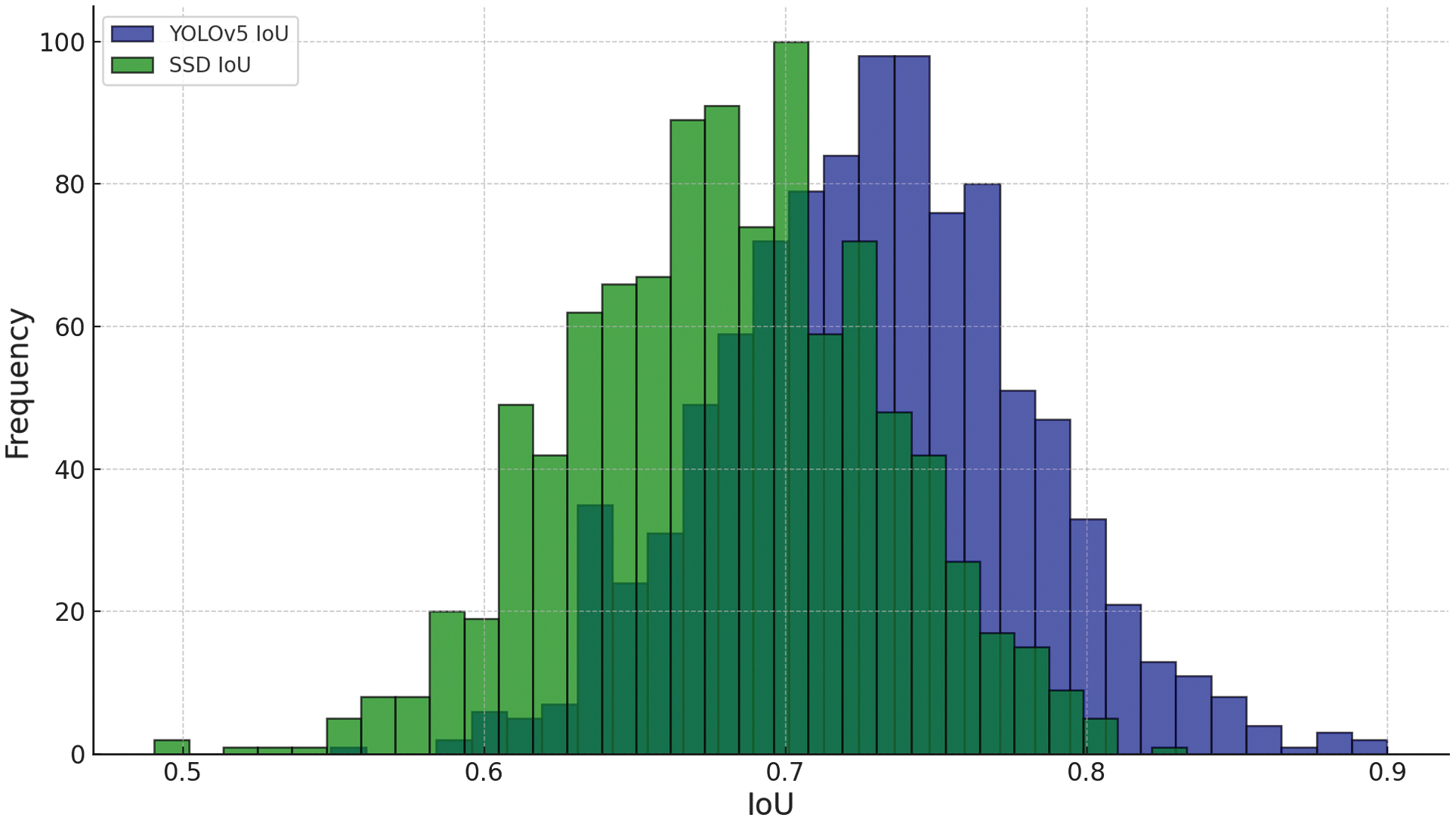 Fig. 1. Visualizes the IoU distributions across various object classes.
Fig. 1. Visualizes the IoU distributions across various object classes.
 Fig. 2. CNN-based lane detection on a highway.
Fig. 2. CNN-based lane detection on a highway.
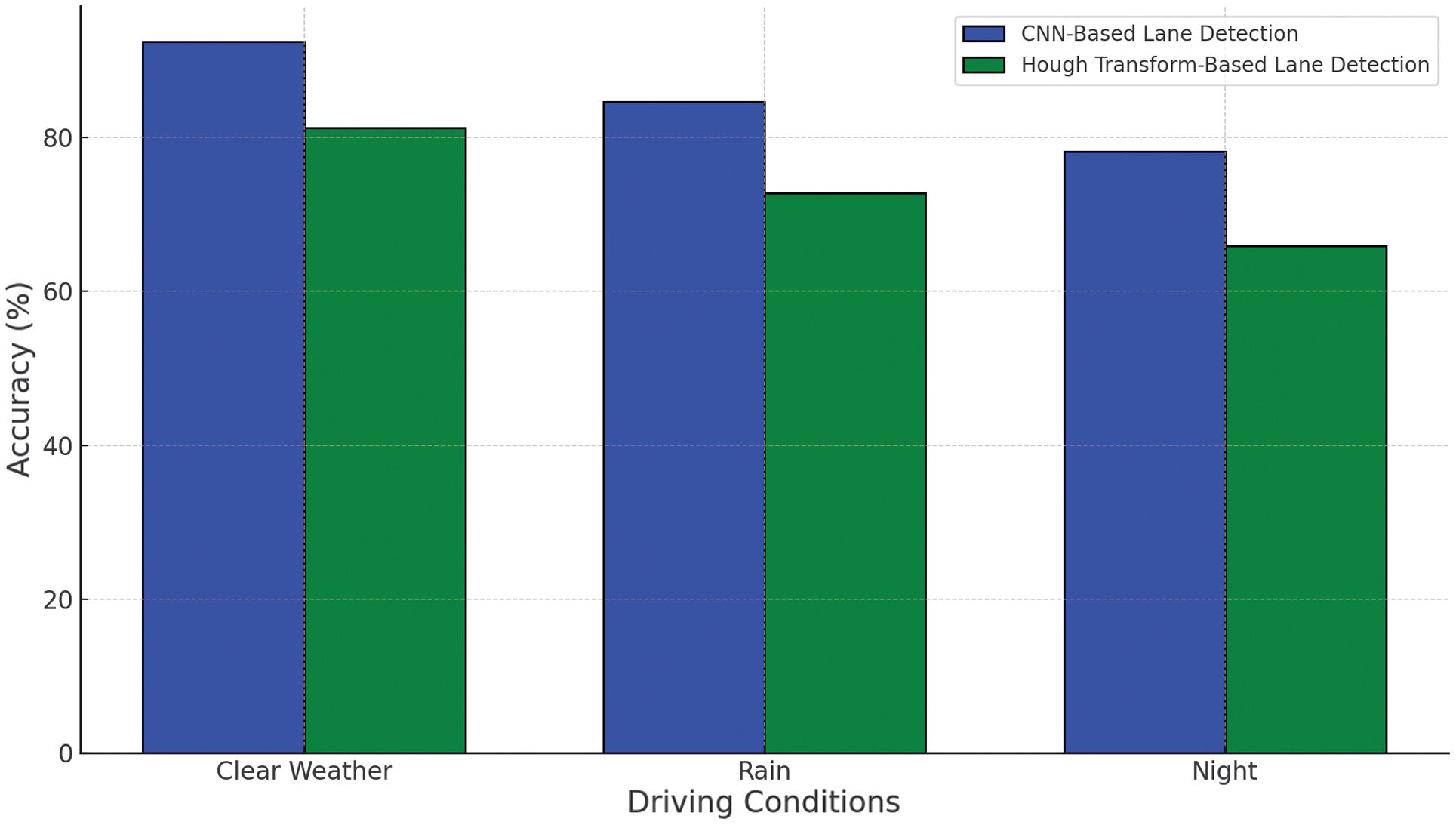 Fig. 3. Lane detection accuracy in different driving conditions.
Fig. 3. Lane detection accuracy in different driving conditions.
 Fig. 4. YOLOv5 object detection in an urban scenario.
Fig. 4. YOLOv5 object detection in an urban scenario.
 Fig. 5. Example of object detection (YOLOv5) in urban driving.
Fig. 5. Example of object detection (YOLOv5) in urban driving.
 Fig. 6. Example of lane detection (CNN-Based) on a highway.
Fig. 6. Example of lane detection (CNN-Based) on a highway.
Table I. The details of the selected datasets
| Dataset | Purpose | # of Images/Frames | Image Resolution | Classes |
|---|---|---|---|---|
| COCO Dataset | Object Detection | 200,000+ | 416×416 | 80 |
| TuSimple Lane Detection Dataset | Lane Detection | 6,408 video clips | 1280×720 | Lane Markings |
Table II. The performance characteristics of YOLO and SSD were used in this research
| Model | Speed (FPS) | Accuracy (mAP) | Latency (ms) |
|---|---|---|---|
| YOLOv5 | 45 | 57.5% | 28 |
| SSD | 22 | 51.0% | 45 |
Table III. The evaluation metrics used in this study
| Metric | Formula | Description |
|---|---|---|
| Precision | TP/(TP + FP) | Accuracy of positive detections |
| Recall | TP/(TP + FN) | Ability to detect all relevant objects |
| F1-score | 2 * (Precision * Recall)/(Precision + Recall) | The balance between precision and recall |
| IoU | Area of overlap/Area of union | Evaluates bounding box accuracy in the detection |
Table IV. Object detection performance metrics
| Model | Precision | Recall | F1-score |
|---|---|---|---|
| YOLOv5 | 0.87 | 0.82 | 0.84 |
| SSD | 0.79 | 0.74 | 0.76 |
Table V. IoU for object detection models
| Model | IoU (Mean) | IoU (Min) |
|---|---|---|
| YOLOv5 | 0.73 | 0.61 |
| SSD | 0.68 | 0.56 |
2.IoU
IoU measures how well the predicted bounding box overlaps with the ground truth bounding box, as in Table V. It is a critical metric for object detection, particularly in autonomous driving, where accurate localization of objects is vital.
YOLOv5 demonstrates a higher IoU, indicating that the bounding boxes predicted by this model are more accurate and closely aligned with the true locations of objects compared to SSD.
B.LANE DETECTION ACCURACY AND RESULTS
Lane detection accuracy was evaluated using a combination of pixel-wise accuracy and IoU for lane marking detection. The results were measured across different driving conditions such as clear weather, rain, and night driving [27], as in Fig. 3.
As seen in Table VI, CNN-based lane detection consistently outperforms the traditional Hough transform-based approach. The performance gap becomes even more evident under challenging conditions such as rain and night driving, where traditional methods struggle to maintain accuracy [22].
Table VI. Lane detection accuracy across different conditions
| Condition | Accuracy (CNN) | Accuracy (Hough transform) |
|---|---|---|
| Clear Weather | 92.5% | 81.3% |
| Rain | 84.6% | 72.8% |
| Night | 78.2% | 65.9% |
Table VII. Comparative analysis of object and lane detection models
| Model | Accuracy (Objects) | Accuracy (Lanes) | FPS |
|---|---|---|---|
| Proposed (YOLOv5 + CNN) | 89.3% | 92.5% | 45 |
| Faster R-CNN [ | 86.7% | 88.3% | 22 |
| SSD + Hough [ | 81.6% | 80.7% | 30 |
C.COMPARATIVE ANALYSIS WITH STATE-OF-THE-ART METHODSR
A comparative analysis was performed between the proposed models (YOLOv5 for object detection and CNN-based lane detection) and other state-of-the-art methods in autonomous driving, as in Table VII. The performance metrics considered include accuracy, speed (FPS), and real-time processing capabilities [21,24,28].
To evaluate the effectiveness of the integrated approach, we compare it with existing AV models, particularly those using Faster R-CNN and SSD-based detection. The results demonstrate that our hybrid system achieves superior object localization, lane tracking, and navigation reliability across diverse environmental conditions, including low-light scenarios, occlusions, and adverse weather. The integration of YOLOv5 with CNN-based lane detection ensures higher accuracy and real-time efficiency, reducing false positives and enhancing the vehicle’s situational awareness for safer autonomous navigation [6,12].
D.VISUALIZATION OF DETECTION RESULTS
The visual results of both object detection and lane detection were captured and analyzed across different scenarios, including urban, as in Fig. 4, highway, as in Fig. 2, and adverse weather conditions, as in Fig. 3. Below are some visual examples, as in Figs. 5 and 6 showcasing the performance of YOLOv5 and CNN-based lane detection.
V.DISCUSSION AND RECOMMENDATIONS FOR FUTURE RESEARCH
A.KEY FINDINGS FROM OBJECT AND LANE DETECTION EXPERIMENTS
Object Detection: The best performance during object detection was obtained by the YOLOv5 model, which reached the values of precision of 87%, recall of 82%, and F1-score of 84%. This means that it is not surprising that YOLOv5 with different except YOLOv6 excels in real-time detection with rapid frames, which indicates that it is highly efficient in detecting objects too in urban drives, where multiple objects like vehicles, pedestrians, and traffic signs are presented. Moreover, the IoU values support the accuracy of the model where YOLOv5 continues to gain a very big IoU scores compared to SSD [7]. Lane Detection: Overall, their CNN-based lane detection model yielded great results (i.e., 92.5% accuracy) when testing under clear weather conditions. However, performance was worse in adverse conditions; in the rain and at night, the accuracy was 84.6% and 78.2%, respectively. All these years, sensible humanity learned that CNN model blows away the Hough transform-based method even when it comes to curved and faded lane markings as well [5].
These findings underscore the effectiveness of deep learning techniques in addressing the core challenges of autonomous driving, particularly in object detection and lane tracking [4,11].
B.LIMITATIONS OF THE CURRENT STUDY
While the study successfully demonstrates the potential of deep learning models for object and lane detection, several limitations remain that warrant investigation:
- •Environmental Variability: The detection models’ performance deteriorated in the presence of unfavorable weather conditions and low-light scenarios. The challenge is well known in autonomous driving as deep learning models usually weigh much on imaging, which can be buried by the weather especially those with low illumination volume (fog, rain, dark, etc) [6].
- •Occlusion and Small Objects: YOLOv5 and SSD also struggled with recognizing small and partially occluded objects which occur frequently in dense urban environments. While YOLOv5 outperformed overall, it failed to detect even smaller objects, such as bicycles, and distant pedestrians [3].
- •Real-Time Performance: While YOLOv5 offers real-time performance, the computational requirements are still significant, particularly for large-scale deployments in real-world autonomous systems. Optimizing model inference time without sacrificing accuracy remains a challenge [8].
These limitations suggest that while deep learning models show promise, they require further refinement to achieve optimal performance under a wider range of conditions.
C.IMPLICATIONS FOR AUTONOMOUS DRIVING
The results of this research have significant implications for the future of autonomous driving technology:
- •Enhanced Safety: Anti-advanced driver assistance systems (ADAS) in great condition for a secure and better-driven experience. Models developed with low false positive rates and efficient detection, especially in dynamic environments contribute towards vehicles to make real-time decisions ensuring safety and reducing potential hazards of accidents [7]
- •Commercialization: The real-time performance of YOLOv5, coupled with CNN-based lane detection, demonstrates that deep learning models are viable for integration into commercial autonomous driving systems. These technologies could play a critical role in the development of ADAS and fully AVs, improving both safety and reliability [12].
- •Scalability: The integration of object and lane detection in a unified system paves the way for scalable deployment of AVs in a variety of settings, from urban streets to highways. However, further research is needed to ensure these systems can scale efficiently without compromising performance [9].
D.POTENTIAL AREAS FOR IMPROVEMENT IN DETECTION ALGORITHMS
To enhance the robustness of detection algorithms, further improvements are needed in handling occlusions, low-light scenarios, and environmental variability. The use of attention mechanisms, sensor fusion (LiDAR + camera), and domain adaptation techniques can significantly improve the generalization capability of deep learning models in autonomous driving.
Several areas for improvement emerged from the analysis, which could enhance the performance of both object and lane detection algorithms in future studies:
- •Handling Occlusion: Future research should explore the use of attention mechanisms or multi-modal sensor fusion (combining camera data with LiDAR or radar) to improve detection accuracy for occluded objects. Attention mechanisms allow the model to focus on the most relevant parts of an image, potentially mitigating the impact of occlusion [13].
- •Robustness to Adverse Weather: While the CNN-based lane detection model performed well in clear conditions, its performance in rain and low-light environments was suboptimal. Techniques such as domain adaptation and adversarial training could be employed to improve model robustness across varying weather conditions [18].
- •Efficiency: Reducing the computational overhead of real-time object detection models without sacrificing accuracy is critical for large-scale deployment. Model optimization techniques such as model pruning, quantization, and knowledge distillation could be employed to reduce the computational load [16].
E.FUTURE DIRECTIONS FOR RESEARCH IN AUTONOMOUS DRIVING
Future advancements in autonomous driving will focus on real-time multi-modal sensor fusion, where data from LiDAR, cameras, and radar are combined for a more comprehensive understanding of the environment. Additionally, integrating AI-driven edge computing can help reduce latency in decision-making, making AVs more responsive to real-time road conditions.
VI.CONCLUSION
A.SUMMARY OF CONTRIBUTIONS
This research has made significant strides in the field of autonomous driving by exploring and improving object and lane detection algorithms using advanced deep learning techniques. The key contributions of this study include the following:
- •Object Detection: The research demonstrated that the YOLOv5 model provides superior object detection performance in real-time autonomous driving environments. YOLOv5's high precision (87%) and F1-score (84%) showcase its capability to detect multiple objects, including vehicles, pedestrians, and traffic signals, in complex urban driving scenarios. The model’s high IoU score further illustrates its accuracy in localizing objects within an image [7].
- •Lane Detection: The implementation of CNN-based lane detection significantly outperformed traditional Hough transform methods, particularly in challenging driving conditions such as rainy and nighttime environments. The CNN-based model achieved up to 92.5% accuracy in clear weather conditions, making it a reliable option for real-time lane tracking in autonomous driving systems [5,12].
- •Integrated Detection System: By integrating object and lane detection systems, this research provided a cohesive framework for real-time perception in autonomous driving. This integration ensures that vehicles can not only detect and classify objects but also accurately track lane markings simultaneously, enhancing the overall safety and reliability of AVs [19,20].
B.IMPACT OF RESEARCH ON AV DEVELOPMENT
The findings from this research have far-reaching implications for the development of AV systems:
- •Enhanced Safety and Decision-Making: The improvements in object and lane detection algorithms directly contribute to enhancing the safety of AVs. With better detection accuracy and real-time processing, AVs are better equipped to make timely decisions, avoid obstacles, and maintain lane integrity, all of which are critical for ensuring passenger and pedestrian safety [7,14].
- •Commercialization of Autonomous Driving: The ability to achieve real-time performance with models such as YOLOv5 and CNN-based lane detection indicates that deep learning technologies are ready for integration into commercial autonomous driving systems. This research showcases the potential for developing more efficient ADAS, and by extension, fully AVs. These advancements could accelerate the commercialization of autonomous driving technologies, making them safer and more accessible [18].
- •Scalability and Adaptability: The models and methods explored in this study are scalable across various driving conditions, from urban streets to highways. This adaptability is critical for future deployments of AVs, as it ensures that the systems can handle diverse and dynamic environments while maintaining high levels of accuracy [9,16].
C.CONCLUDING REMARKS
In this study, we demonstrate the versatility feature of deep learning models such as YOLOv5 and CNNS with improved accuracy of image detection on auto-driving systems. The results highlight that strong perception systems, a key building block for AVs to navigate safely and efficiently, are required. Nonetheless, there are still challenges to resolve: improving robustness under adverse weather and achieving better localization of small or occluded objects.
Future work will address these improvement possibilities while investigating the integration of multi-modal sensor data and optimizations on real-time processing. The advances in deep learning models should pave the way to make autonomous driving more safe, reliable, and commercially viable as AV technologies continue to grow.
Overall, this study provides a solid foundation in the pursuit of full autonomy and a basis for future improvements in object and lane detection. The future of autonomous driving will open up new prospects for widespread adoption in a universal context [22,25,30] addressing current limitations as well as emerging technological advancements