I.INTRODUCTION
Converged networks, in which several services are integrated across a single infrastructure, are the result of a paradigm shift brought about by the expansion of high-speed Internet services and the exponential development of network traffic. Numerous advantages have resulted from this convergence, such as increased network scalability, decreased operational costs, and enhanced efficiency. But it also presents a lot of difficulties, especially when it comes to guaranteeing quality of service (QoS) and maximizing bandwidth distribution. Traditional bandwidth allocation strategies are insufficient due to the different requirements of different applications and the restricted availability of network resources. This results in inefficient network performance and reduced QoS. It is now essential to design intelligent network management systems that can dynamically allot bandwidth in response to circumstances of the network and application needs in real time. This problem seems to have a possible answer in deep learning, which is unmatched in its capacity to recognize intricate patterns and make deft judgments. Even while deep learning-based network management is becoming more and more popular, most of the research so far has concentrated on theoretical frameworks and simulations, paying little attention to real-world validation or practical implementation. In order to fill this gap, this research suggests a revolutionary deep learning method for convergent networks that optimizes bandwidth allocation. We create and use three deep learning models: Deep Q-Networks (DQNs), Generative Adversarial Networks (GANs), and a special Long Short-Term Memory (LSTM)-based DQN model. We assess each model’s performance using an extensive dataset. With the help of our study, intelligent network management solutions will be developed, facilitating more effective bandwidth allocation, better QoS, and better user experiences in converged networks.
A.GENERATIVE ADVERSARIAL NETWORK (GAN)
Generator Loss:
Deep learning models called GANs use a two-player game framework to create artificial data that mimics real data. The pair of participants are as follows:
- 1.Generator: A neural network that creates artificial data using random noise as input. Usually a variational autoencoder (VAE) or a transposed convolutional neural network (TCNN).
- 2.Discriminator: A neural network that can distinguish between bogus and real data by using both types of input. A convolutional neural network (CNN) is commonly used.
Training Process:
Step 1: Use both synthetic data produced by the generator and real data to train the discriminator.
Step 2: Teach the generator to create fake data that deceives the discriminator.
Steps 1–2 should be repeated until convergence.
Its benefits include learning difficult data distributions and producing extremely realistic data. Both the discriminator and the generator are trained simultaneously, with the discriminator attempting to accurately discern between real and fake data and the generator attempting to generate more realistic data. The performance of both networks improves as a result of this antagonistic dynamic. This method is typically applied to anomaly detection, data enrichment, and the creation of images and videos.
B.DEEP Q-NETWORK (DQN)
DQNs are a class of reinforcement learning (RL) model that approximates the Q-function—a measure of the expected reward or return for an action in a given state—using a neural network. It can learn complex Q-functions and handle high-dimensional state and action spaces. It is mostly utilized in robots, autonomous cars, and gaming.
Important Elements:
- 1.State: The condition of the surroundings at the moment.
- 2.Action: The representative’s action.
- 3.Reward: The compensation the agent earned for carrying out the task.
- 4.Q-Network: The neural network via which the Q-function is approximated.
Training Process:
- 1.Set the weights of the Q-Network at random.
- 2.Act under the circumstances at hand.
- 3.Examine the prize and the subsequent stage.
- 4.Apply the Q-learning (QL) update rule to update the Q-Network.
- 5.Continue steps 2–4 until they are reached.
C.HYBRID DEEP Q-LEARNING (DQL) MODEL
A LSTM layer is used by the Hybrid Deep Q-Learning (DQL) model, a variation of the DQN model, to incorporate temporal dependencies in the data. This technique is mostly used in predicting time series, making decisions in sequence, systems with autonomy.
Key Components:
- 1.State: The state of the surroundings as of right now.
- 2.Activity: The agent’s actual activity.
- 3.Reward: The benefit the agent obtained for carrying out the action.
- 4.LSTM Layer: The temporal dependencies in the data are captured by this LSTM layer.
The neural network that approximates the Q-function is known as the Q-Network.
Training Process:
- 1.Set random weights for the LSTM layer and Q-Network.
- 2.Act under the circumstances at hand.
- 3.Examine the prize and the subsequent stage.
- 4.Apply the QL update rule to update the LSTM layer and Q-Network.
- 5.Continue steps 2–4 until they are reached.
Architecture:
- a)Q-Network: Generally, a fully connected neural network or a CNN.
- b)LSTM Layer: An LSTM can be single or multilayered.
While the DQN and Novel DQN models are used to estimate the bandwidth allocation, the GAN model is utilized to generate new data samples. The Novel DQN model is appropriate for sequential decision-making tasks since it uses LSTM to add temporal dependencies. Table I shows the major differences among the three methods used in the paper.
Table I. Comparison of the methods implemented
| Feature | Generative adversarial networks (GANs) | Deep Q-Learning (DQL) | Novel DQL model |
|---|---|---|---|
| Unsupervised learning | Reinforcement learning | Reinforcement learning | |
| Two neural networks: Generator and Discriminator | Single neural network (or DNN) paired with Q-learning | Enhanced neural network architecture (e.g., Double DQN, Dueling DQN) | |
| Generate data that mimics real data | Learn an optimal policy to maximize cumulative reward | Improve learning stability, convergence, and performance over standard DQL | |
| Adversarial training between Generator and Discriminator | Agent interacts with the environment, updates Q-values based on rewards | Similar to DQL, but often includes improvements like prioritized experience replay, double Q-learning | |
| Image generation, text generation, data augmentation | Game playing (e.g., Atari), robotics, path planning | Similar to DQL, but used in more complex or unstable environments | |
| Minimax loss for Generator and Discriminator | Bellman equation, mean-squared error for Q-value updates | Modified Bellman equation, often with improved stability measures | |
| N/A (GANs are not RL-based) | Balances exploration and exploitation using ɛ-greedy strategies | Similar to DQL but with enhanced exploration-exploitation mechanisms (e.g., using intrinsic motivation) | |
| Alternates between updating the Generator and the Discriminator | Updates Q-values after each action based on the reward received | Incorporates advanced techniques like experience replay or target networks to improve learning efficiency | |
| Requires a large amount of data to generate realistic samples | Requires interaction with an environment to gather data (rewards) | Same as DQL, but often with improved data efficiency through methods like prioritized experience replay | |
| Training instability, mode collapse, sensitivity to hyperparameters | High sample inefficiency, instability with function approximation | Tackles DQL challenges with techniques like target networks, double Q-learning |
Optical network units (ONUs) and optical line terminals (OLTs) are essential components of contemporary telecommunication systems that enable high-speed data transmission over convergent networks. ONUs enable smooth connection between end users and the central network by converting optical impulses to electrical signals. They are usually installed at client premises. Several ONUs are managed by OLTs, which are located in the central office. They aggregate and groom traffic to guarantee effective data transfer. In converged networks—where several services—like voice, video, and data coexist—adaptive bandwidth allocation is crucial. Network operators can maximize resource usage and provide QoS for important applications by dynamically changing bandwidth allocation based on real-time traffic demands. QoS characteristics, including as packet loss, jitter, and delay, are carefully controlled to provide continuous services. Converged networks provide special difficulties since they combine data, video, and voice services onto a single infrastructure. But their advantages—lower operating costs, easier network management, and more scalability—make them a compelling offer. Network operators use cutting-edge technology like Software-Defined Networking (SDN) and Multiprotocol Label Switching (MPLS) to handle the complexity by allowing adaptive bandwidth allocation and intelligent traffic management. Delivering high-performance convergent networks will depend on the cooperation of ONUs, OLTs, adaptive bandwidth allocation, and QoS as network demands change in the future. Network operators can guarantee a better user experience and encourage the broad adoption of bandwidth-intensive services by utilizing these technologies.
Through its ability to estimate network traffic patterns, identify possible areas of congestion, and facilitate proactive resource allocation, predictive analytics can be a valuable tool in improving the data rate in ONUs. The discount factor, commonly represented by γ (gamma), is utilized to assess the relative significance of both present and future benefits. It establishes the agent’s value judgment for future benefits in relation to current rewards. The discount factor often falls between 0.9 and 0.99. Long-term rewards are prioritized by selecting a number closer to 1, whereas short-term rewards are prioritized by selecting a value closer to 0. It is most likely using the default value of 0.99, which is a popular option for many RL implementations.
One essential part of a passive optical network (PON) is an ONU. It is located on the subscriber’s property and has an optical fiber connection to the OLT. Residential ONUs typically allows data rates upstream (from ONU to OLT) of up to 1 Gbps and downstream (from OLT to ONU) of 100 Mbps to 1 Gbps. The kind of PON technology utilized, such as Ethernet PON (EPON) or Gigabit PON (GPON), frequently affects the data rates. Higher data speeds, ranging from 1 Gbps to 10 Gbps, may be available from business-grade ONUs based on bandwidth and QoS needs. VoIP, video conferencing, and high-speed Internet are among the services they support. Even greater data speeds are supported by emerging technologies like NG-PON2 (Next-Generation PON 2) and XG-PON (10 Gbps PON), which have the ability to provide 10 Gbps for both downstream and upstream connections. As the distance from the OLT increases, signal attenuation may cause a decline in data rate. Data rate is also affected by the optical network’s architecture and the existence of splitters. In order to calculate a passive optical network’s data rate, both ONUs and OLTs are essential. OLTs oversee and combine traffic for several ONUs, whereas ONUs is in charge of providing services to end customers. The kind of PON technology being utilized, the setup of the network, and particular hardware features all affect these components’ data rates. PON technology developments are continuously pushing the limits of possible data rates as network demands rise, providing quicker and more dependable Internet access. The distance between OLT and ONU, network congestion, fiber quality and length, and optical signal strength are all factors that affect data rate.
D.LIST OF NOVEL METHODS TO IMPROVE DATA RATES AT ONU
There are a number of creative ways to apply novelty in deep learning to improve predictive analytics for higher data rates in ONUs. The following Table II shows the top methods and strategies used in the literature available, for improving the data rates at ONU. ONUs may be made more capable of handling growing data rates by utilizing these predictive analytics techniques, guaranteeing a more dependable and seamless network experience.
Table II. Deep learning approaches to improve data rates
| Novel technique | Description | Benefits |
|---|---|---|
| Self-attention mechanisms | Improves focus on relevant input sequences within LSTMs. | Enhanced prediction accuracy. |
| Transformers | Handles long-term dependencies and parallelizes training. | Efficient and scalable prediction. |
| Spatio-temporal graph convolutional networks | Captures spatial and temporal dependencies in traffic data. | Nuanced and accurate predictions. |
| Hybrid CNN-LSTM models | Combines spatial feature extraction with temporal prediction. | Comprehensive pattern recognition. |
| GANs for data augmentation | Generates synthetic traffic data for training. | Improved model robustness. |
| Model-agnostic meta-learning (MAML) | Enables quick adaptation to new traffic patterns. | Better generalization in dynamic environments. |
| Federated learning | Decentralized model training across multiple devices. | Enhanced privacy and diverse learning. |
| RL for dynamic bandwidth allocation | Optimizes bandwidth allocation based on traffic predictions. | More efficient network management. |
| Multi-agent RL | Coordinated optimization across different network segments. | Improved resource allocation and performance. |
| Variational autoencoders (VAEs) | Detects anomalies in traffic patterns. | Preemptive network management. |
| Sequence-to-sequence autoencoders | Learns compressed representations for end-to-end prediction. | Accurate traffic forecasting. |
| Pretrained models | Fine-tuning on specific datasets for better performance. | Reduced training time and improved results. |
| Domain adaptation | Transfers knowledge across different network environments. | Enhanced model robustness and adaptability. |
The paper calculates and compares few important parameters of the converged networks, whose mathematical expressions (1–8) are given as below:
- 1.Packet Loss Rate (PLR):
- 2.Accuracy:
- 3.Latency:Latency = Average time taken for data transmission from source to destination
- 4.Throughput:Throughput = Total amount of data transmitted/Total time taken for transmission where packet size is the size of each packet, t_n is the time of arrival of the last packet, and t_0 is the time of transmission of the first packet.
- 5.Spectral Efficiency (SE):
- 6.Bit Error Rate (BER):
- 7.Fairness Index (FI):where throughput of user i is the throughput achieved by user i and n is the total number of users.
- 8.Channel Utilization Ratio (CUR):
E.DISCUSSION ON THE LITERATURE AVAILABLE ON THE RESEARCH TOPIC
Yapeng Xie and colleagues have shown how machine learning (ML) approaches have emerged as a crucial remedy for numerous difficult problems. In particular, ML has received a lot of attention in the fields of short-reach optical communications, signal processing, modulation format identification (MFI), optical performance monitoring (OPM), and in-building/indoor optical wireless communications. This is due to ML’s high accuracy, adaptability, and implementation efficiency [1]. An OLR-based dynamic wavelength and bandwidth allocation (DWBA) method for the upstream channel in the next-generation Ethernet passive optical network (NG-EPON) has been proposed by Hui et al. [2]. A container with finer bandwidth granularity, the optical service unit (OSU), was proposed by Qiaojun Hu et al. [3]. A mixed integer nonlinear software developed by Sourav et al. can be used to determine the best places for cloudlet placement in urban, suburban, and rural deployment settings. The authors demonstrate that a key factor in deciding how much compute power to install in the cloudlets is the goal latency requirement as well as the kind of deployment scenario. Additionally, they demonstrate that the access networks’ incremental energy budget as a result of active cloudlet installation is less than 18%. In summary, the authors’ findings indicate that the recently suggested hybrid cloudlet placement framework outperforms the field cloudlet deployment paradigm in terms of cost-effectiveness [4]. In order to address the issue of heterogeneous ONU propagation delays for low-latency and energy-efficient EPONs, Li et al. have suggested a resource allocation mechanism. In order to achieve low latency and energy efficiency, the scheme first predicts the upstream (US) and downstream (DS) bandwidth requirements of each ONU. Based on these predictions, the scheme then arranges the ONU polling sequence and the US and DS transmissions of each ONU [5]. It has been suggested that coordinated digital subscriber line (DSL) networks operate better when far-end crosstalk is reduced. The partial crosstalk cancelation of joint tone-line selection (JTLS) significantly lowers the transmission’s online computing cost. Numerous algorithms were examined; however, they failed to evaluate the impact of discrete bit-loading on the selection process. This study formulates the JTLS partial crosstalk cancelation problem in the discrete information allocation scenario of multicarrier DSL systems. To address the solution, an algorithm based on genetics is suggested. To do the crosstalk selection, its parameters are assessed [6]. Two approaches have been discussed by Yunxin et al. to address ONU time delays. The first solution, known as the Upstream Postponing with ONU Dozing (UP-OD) scheme, involves incorporating ONU doze mode to improve network energy efficiency and appropriately postponing the upstream transmissions of those ONUs with relatively short propagation delays to improve channel utilization efficiency. The second approach, known as the Identical Fiber Length with ONU Sleeping (IFL-OS) scheme, involves implementing ONU sleep mode to reduce energy consumption and adopting an identical distribution fiber length for ONUs in order to improve channel utilization [7]. According to Huang et al., a differential output receiver is employed to lower system noise, and a pre-equalization circuit is used to increase the modulation bandwidth. The authors experimentally established a 2.0-Gb/s visible light link over 1.5-m free-space transmission using adaptive bit and power allocation and orthogonal frequency-division multiplexing (OFDM), with a BER under a pre-forward error correction limit [8]. The adaptive scheduling approach that Akerele et al. have devised enables wireless sensor networks (WSNs) to collaborate with the ONU to shorten the latency for high-priority traffic. The authors ascertain how the suggested mechanism affects end-to-end delay and reliability as well as the QoS of delay-critical smart grid monitoring applications. Using simulations, the authors demonstrated how our proposed QoS mechanism can lower the end-to-end delay in both long-reach passive optical networks (LR-PONs) and the Fi-WSN system.
The adaptive scheduling approach that Akerele et al. have devised enables WSNs to collaborate with the ONU to shorten the latency for high-priority traffic. Using simulations, the authors demonstrate how they proposed QoS mechanism can lower the end-to-end delay in both LR-PONs and the Fi-WSN system. [9]. A deep RL model for adaptive bandwidth distribution in fiber-wireless convergent networks has been presented by Liu et al., taking into account the dynamic nature of traffic demands. Comparing the model to fixed allocation schemes, the methodology improves network speed and capacity usage dramatically [10]. An orthogonal frequency division multiple access-based passive optical network with an all-optical virtual private network (VPN) enabling dynamic bandwidth allocation (DBA) has been proposed by Kim et al. Using a microwave photonic bandpass filter (MP-BPF), the VPN signal can be transmitted without requiring any electrical conversion. By changing the MP-BPF’s free spectral range and allocating appropriate subcarriers, the DBA is put into practice [11]. In a modified ONoC, Kim et al. have presented optical signal-to-noise ratio (OSNR)-aware wavelength allocation and branching algorithms for multicast routing (OWBM) that are suited for an hybrid graph coloring (HGC) platform. By creating independent routing paths in the divided destination nodes that ensure no routing path overlaps between the partitions, OWBM improves the efficiency of the wavelength resource [12]. A 20 km standard single-mode fiber is used to show hexagonal QAM-based 4D Asynchronous Mach Optical-OFDM transmission for two ONUs with a total data rate of 21 Gbps. Park et al. have studied this topic [13]. In order to address the heterogeneous ONU delays issue for low-latency and energy-efficient EPONs, Li et al. have suggested a resource allocation scheme [14]. In order to enable elastic optical networks to dynamically allocate bandwidth in a way that can adapt to changing demand, Wang et al. have studied the use of deep RL [15]. A method that successfully lowers network latency and boosts energy efficiency has been proposed by Li et al. The suggested approach can lower the average one-way packet delay by at least 28.9% when compared to the traditional Interleaved Polling with Adaptive Cycle Time scheme, which uses the ONU doze mode and the shortest propagation delay first rule [14]. In an effort to improve network efficiency and responsiveness, Shi et al. have investigated the combination of edge computing and RL for dynamic bandwidth distribution in optical networks [16].
An algorithm presented by Sandra et al. outperforms conventional fixed and random allocation techniques by 60–70% [17]. For dynamic traffic in elastic optical networks (EON), Khan et al. have suggested a strategy that combines the advantages of adaptive and fixed alternate routing. Simulation results demonstrate that the suggested approach, when compared to fixed alternate routing and an existing constrained-lower-indexed-block (CLIB)-based adaptive routing algorithm, efficiently enhances the performance of routing, spectrum, and allocation (RSA) in EON and minimizes the quantity of blocking probability points [18]. In an ONoC built for an HGC platform, Kim et al. have presented OSNR-aware wavelength allocation and branching algorithms for multicast routing (OWBM). By creating distinct routing paths in the divided destination nodes, OWBM improves the efficiency of wavelength resources by ensuring that no routing path overlaps with any other partition [12]. Reducing fragmentation, Lohani et al. have provided an improvised RSA algorithm that uses consecutive spectrum slots as an adjustable parameter. The results clearly show that the adaptive parameters used in the current RSA algorithm minimizes the blockage probability and fragmentation more effectively than the shortest path and k-shortest path algorithms that were previously published in the literature [19]. Three parallel 4QAM, 16QAM, or 64QAM OFDMA data broadcast over three sub-channels is more appropriate for different sub-channel allocations, according to Chao et al.’s research [20]. Guo et al. created an effective heuristic to optimize the use of regenerators and spectra in the Regenerator Sharing, Adaptive Modulation, Routing, and Spectrum Assignment (RMRS) problem [21]. In order to accommodate high-bandwidth, all-optically routed packets, Lai et al. have developed an intelligent cross-layer enabled network node that makes use of new photonic technologies such as optical packet switched fabrics and packet-scale performance monitoring. The node may dynamically optimize optical switching based on quality-of-transmission parameters like BERs and link integrity, as well as higher-layer limitations like energy consumption and quality-of-service requirements, by utilizing a cross-layer control and management plane [22]. In order to fully utilize the channel capacity in nonideal channel conditions, Chen et al. proposed a 3-D adaptive loading algorithm (ALA) for DDO-OFDM. This algorithm is capable of allocating modulation formats, power levels, and forward error correction (FEC) codes for each subcarrier. The suggested ALA adds the FEC code, a new degree of freedom, in comparison to the regular ALA. In the meantime, look-up table operations are added to guarantee quick allocation and minimal complexity without sacrificing speed [23]. Na Chen et al. have concentrated on the issues of energy consumption and spectrum sharing with millimeter wave radio over fiber, which is used to improve the system’s coverage. The following steps are part of the suggested adaptive scheme. First, the users are classified by the system as either licensed users, who are the primary owners of the designated spectrum, or unlicensed users, who must buy the spectrum. The sharing of the spectrum resource between eNB and low-power nodes (LPNs) has relatively high utility, according to game theory. Second, to lower the power cost of some LPNs that score below the threshold, an adaptive sleep scheduling system is implemented [24]. Investigated were two solutions put up by Yunxin et al. The first solution, known as the UP-OD scheme, involves incorporating ONU doze mode to improve network energy efficiency and appropriately postponing the upstream transmissions of those ONUs with relatively short propagation delays to improve channel utilization efficiency. The second approach, known as the IFL-OS scheme, involves implementing ONU sleep mode to reduce energy consumption and adopting an identical distribution fiber length for ONUs in order to improve channel utilization [25]. In order to train and learn from past DS judgments, Zhuofan et al. have proposed using the QL technique, which can greatly reduce the data access delay. But there are two obstacles in the way of QL’s widespread adoption in data centers. Massive amounts of input data and blindness regarding parameter settings seriously impede the learning process’s convergence. They have created an evolutionary QL scheme known as LFDS (Low latency and Fast convergence Data Storage) in order to address these two major issues [26]. The suggested approach has been assessed by Bichen et al. using well-known datasets and compared its results to well-known state-of-the-art algorithms. The authors demonstrated that despite being asynchronous and distributed, it can achieve performance that is on par with or even better than state-of-the-art algorithms as they exist today [27]. Siddiqui et al. discovered that their suggested method can yield competitive results when comparing it to trust-region limited algorithms and sequential least squares programming [28]. To solve this issue and optimize user experience, Khoi et al. suggest using RL, an effective simulation-based optimization approach. The authors primary contribution is the unique, noncooperative, real-time technique we suggest, based on deep RL, to address the energy-efficient power allocation problem in D2D communication while meeting QoS requirements [29]. When the channel is unable to accommodate every vehicle’s resource request, Nguyen et al.’s risk-based transmission control can be a great addition to relieve congestion. At most, the authors congestion control method’s risk assessment-based approach can offer new insights to improve Decentralized Congestion Control (DCC) for 5G V2X side link in the upcoming specifications. [30]. In order to provide an explanation of H2M application delivery, Ruan et al. removed the report-then-grant procedure from the current bandwidth allocation systems. The authors thoroughly examine the latency performance of ALL and current methods through extensive simulations that are loaded with experimental traffic traces. The authors findings confirm ALL’s excellent capacity to reduce latency and constrain it for H2M applications [31]. A criterion for identifying candidate or possible virtualized network functions (VNFs) for decomposition as well as the level of granularity of that decomposition has been devised by Chetty et al. It is difficult to model and solve the joint challenge of decomposition and efficient embedding of microservices using precise mathematical models. As a result, the authors used Double DQL to create a RL model. This demonstrated that the microservice strategy had an almost 50% higher normalized Service Acceptance Rate (SAR) than the monolithic deployment of VNFs [32]. The resource allocation problem can be solved by Sandra et al. using the BB algorithm, which maximizes the utilization efficiency of available resources by 60–70% in comparison to a baseline situation [33]. DistADMM-PVS has been shown by Anqi et al. to decrease the network’s average latency while also ensuring acceptable latency performance for all supported service types. DistADMM-PVS converges significantly faster than several other known algorithms, according to simulation data [34]. According to Wai-Xi-Liu et al., in order to enhance the scheduling policy, DRL-PLink introduces novel technologies for deep deterministic policy gradient to address function approximation error, such as clipped double QL, exploration with noise, and prioritized experience replay. These technologies also induce greater and more randomness for exploration, as well as more effective and efficient experience replay in DRL. The experiment’s outcomes show that DRL-PLink can efficiently plan mix-flows at a minimal system overhead under real datacenter network workloads, such as Web search and data mining workloads [35]. A task offloading technique based on RL computing has been presented by Kun Wang et al. for the Internet of vehicles’ edge computing architecture. First, the Internet of vehicles system architecture is created. While the control center gathers all vehicle data, the Road Side Unit receives vehicle data in the neighborhood and sends it to the Mobile Edge Computing server for data analysis. Then, in order to guarantee the rationality of work offloading in the Internet of cars, the computation model, communication model, interference model, and privacy issues are established [36]. In multilayer optical networks, hybrid DQN for real-time bandwidth allocation has been covered by Liu et al. [37]. Vajd et al. have talked about how future technological advancements could affect the outcomes, such as adding more radio antenna ports and fine-tuning the fiber spectrum grid [38]. Ning et al. have described how experimental observations and characterizations of the photomultiplier tube (PMT) saturation-induced bandwidth restriction and underwater optical communication system performance deterioration are made for a range of optical intensity and PMT gain [39]. AI methods for dynamically assigning bandwidth in 5G optical networks have been covered by Li B et al. [40]. An adaptive scheduling approach for the coexistence of ONUs with varying tuning times in virtual PON has been suggested by Wang et al. as the multi-tuning-time ONU scheduling (MOS) algorithm#. The simulation results show that the MOS algorithm can successfully prevent the additional queue delay brought on by the wavelength tuning of ONUs, improving load balancing and cutting down on bandwidth resource waste as a result [41]. A type of adaptive single-mode fiber coupling system based on an enhanced control method called precise-delayed stochastic parallel gradient descent (PD-SPGD) and a novel corrector called adaptive fiber coupler has been studied by Guan et al. In contrast to the prior SPGD algorithm, PD-SPGD can set a precise temporal delay between the disturbed voltages and the performance metrics, thereby compensating for the controlled system’s intrinsic response delay [42].
II.METHODOLOGY IMPLEMENTED
A multilayer perceptron (MLP) architecture is proposed that implements RL. Pandas and Scikit-learn libraries were used.
RL is an algorithm that learns via trial and error through interaction with its surroundings as shown in Fig. 1. This process is known as reinforcement learning, or RL for short. Rewarding desired actions and penalizing undesired ones is how RL works, in contrast to classical ML, which needs a large dataset of labeled samples. As a result, they can gradually enhance their performance and adjust to new circumstances. From teaching computers to play intricate games like chess to streamlining traffic in cities, RL has many uses. Learning without explicit programming is a key feature of RL, making it an effective technique for creating intelligent robots that can do intricate tasks in dynamic contexts.
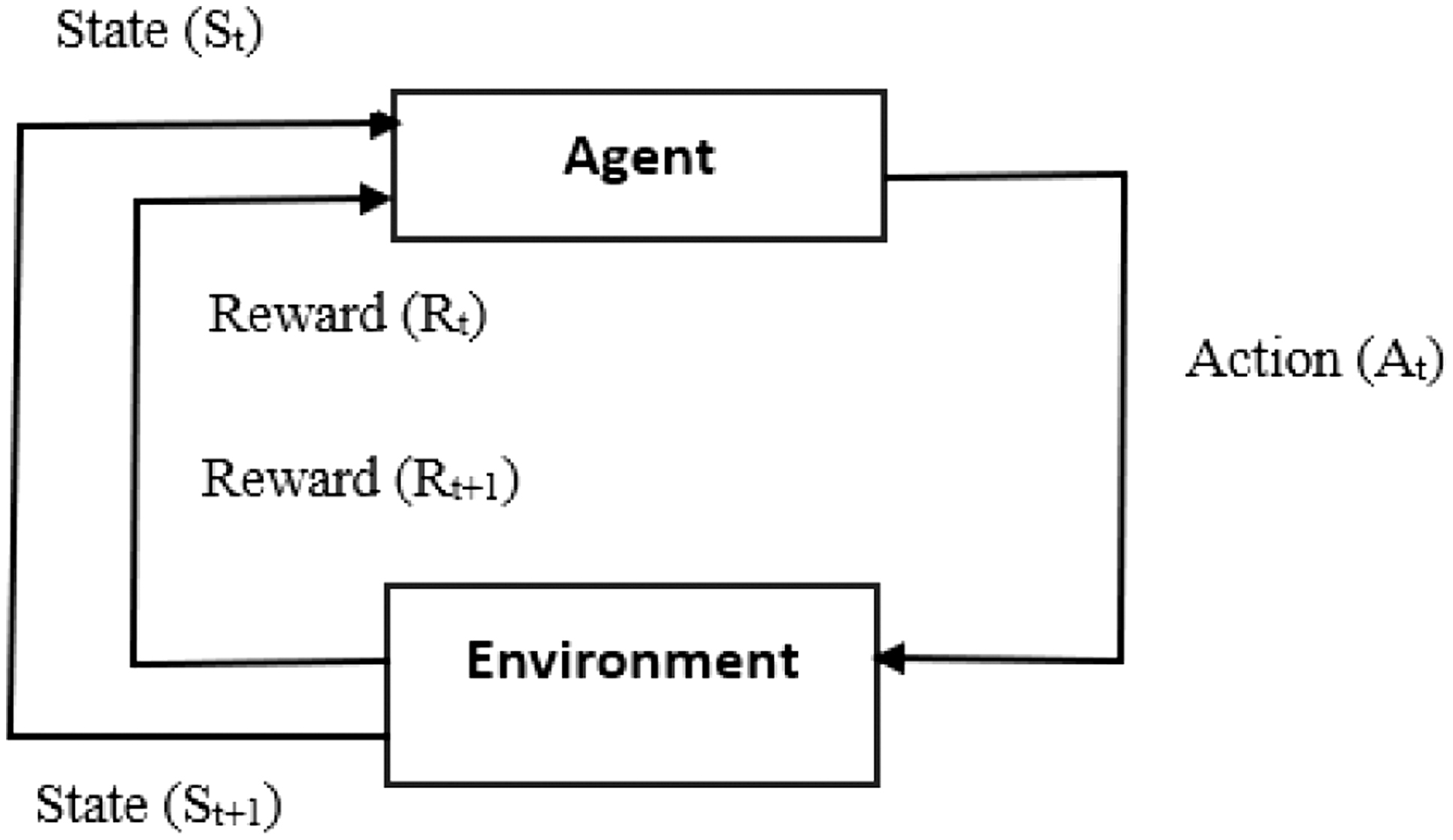 Fig. 1. Reinforcement learning.
Fig. 1. Reinforcement learning.
A.AI AND RL TO INCREASE DATA RATE
- 1.Forward Error Correction (FEC) and Dynamic Signal Modulation using AI:
The challenge is to find the best compromise between FEC code (stronger codes limit data rate but correct errors) and modulation format (higher-order forms transport more data but are more susceptible to noise). Utilizing real-time network data—such as signal strength, noise levels, and traffic patterns—train an AI model. Then, on a per-link basis, the model may dynamically modify the FEC code and modulation format to maximize data rate and reduce mistakes (Fig. 2).
- 2.Adjusting for Dispersion Using RL
Data rate is limited by chromatic dispersion, also known as signal spreading. While network circumstances change, traditional dispersion correction approaches may not be the best option because they are static. Implemented a real-time compensation setting adjustment RL agent that continuously tracks dispersion levels. Optimizing dispersion compensation for maximum data flow, the agent gains experience through trial and error. The AI Fix Using data from real-time networks (signal strength, noise levels, and traffic patterns) train an AI model. Afterward, the model may dynamically modify the FEC code and modulation format for each link, optimizing data rate and reducing mistakes.
- 3.AI-Powered Proactive Network Optimization
Congestion and bottlenecks in the network can drastically lower data rate. Conventional optimization techniques require human involvement. Create a network management system driven by AI. It has the ability to forecast possible bottlenecks by analyzing traffic patterns. Through proactive optimization of network performance for increased data rates, the system can make adjustments to routing protocols and resource allocation.
- 4.Combined AI and RL Optimization
Optimizing the network’s dispersion, routing, and modulation all at once turns into a challenging issue with several moving parts. Use RL for in-the-moment modifications and AI for high-level network planning. While the RL agent optimizes specific components based on real-time input, the AI can specify the overarching goals of the network.
B.OVERALL MLP IMPLEMENTED
The overall process for forecasting node counts in an optical interconnection network with an artificial neural network called a MLP regressor. The general technique can be extended to a variety of scenarios including data preprocessing, model training, and evaluation.
- a.Data Loading and Cleaning (Preprocessing):
The dataset, which is usually saved in a CSV file or another structured format, must be loaded first. Features (independent variables) in this dataset have the potential to affect the target variable, in this case the node number.
To guarantee that the model can learn efficiently, data cleaning is essential. This could entail eliminating rows that have missing values (NaNs), dealing with data type discrepancies (such as translating strings to numbers), and resolving outliers that might distort the model’s learning. Missing values can be addressed and the data distribution can be normalized, respectively, by using methods like data imputation or scaling. The format of categorical features, which stand for nonnumerical variables like “location” or “network type,” must be changed so that ML models may use them. A popular method that generates a new binary feature for every distinct category in the original column is called “one-hot encoding.” This enables the model to discover how these categories relate to the target variable.
- b.Data Splitting and Feature Scaling:
Training and testing sets are then created from the preprocessed data. The model is trained using the training set, usually the greater portion (e.g., 80%). The testing set, such as 20%, is used to gauge how well the model performs on untested data and how generalizable it is. Partitioning the data aids in avoiding overfitting, an occurrence wherein the model retains the training set but exhibits poor performance on novel instances. Feature scaling is frequently used prior to model training. Through this procedure, the characteristics are normalized to a comparable range, usually with a mean of 0 and a standard deviation of 1, or between 0 and 1. Through feature scaling, the model can concentrate on the relative significance of each feature in predicting the target variable, preventing features with bigger scales from controlling the learning process.
- c.Model Training:
After that, the selected ML model is trained using the ready-made training set. Here, a particular kind of artificial neural network called an MLP regressor is employed. Inspired by the architecture and operation of the human brain, neural networks consist of interconnected layers of artificial neurons that can recognize intricate correlations between input data and the target variable. The weights and biases of the neural network connections are iteratively adjusted during the model training process. Based on the discrepancy between the model’s predictions and the actual target values (errors) in the training data, this adjustment is made. By adjusting the weights and biases using an optimization process like gradient descent, the aim is to reduce this mistake as much as possible. Model performance is heavily dependent on training parameters such the number of hidden layers, the number of neurons in each layer, the activation function used in each layer, and the learning rate (step size for weight updates). To get the best outcomes, these factors are frequently found via hyperparameter adjustment and testing.
- d.Model Evaluation:
After training, the model’s effectiveness is assessed using testing data that hasn’t been seen. The model’s accuracy in predicting the target variable is evaluated using metrics such as mean squared error (MSE) or R-squared. The mean squared error between the expected and actual numbers is measured by MSE. Conversely, R-squared shows the percentage of the target variable’s variance that the model explains. It is possible to compare the expected and actual values using visualization techniques such as scatter plots. This facilitates the detection of any potential biases or systematic inaccuracies in the predictions made by the model.
- e.Model Refinement and Deployment:
The model can be improved upon in light of the evaluation’s findings. This might be changing hyperparameters, gathering more training data, or experimenting with other ML techniques. Enhancing the accuracy and generalizability of the model on an ongoing basis is the aim. The model can be used for practical applications after it reaches an acceptable degree of performance. This could entail using the model to real-time prediction on newly collected network data or incorporating it into a network management system.
An overview of the ML process for forecasting node numbers in an optical interconnection network is given in this breakdown. The particulars of the implementation may change based on the ML model, selected libraries, and data properties. Nonetheless, the fundamental ideas behind data pretreatment, model training, assessment, and improvement hold true for all ML uses.
C.USING AI AND RL IN A NOVEL WAY TO INCREASE DATA RATE IN OPTICAL FIBER CABLE (OFC) NETWORKS
While optical fiber cable (OFC) networks can benefit from higher data speeds thanks to AI and RL, real originality demands surpassing current methods. The following are some crucial areas for innovation:
1)USING RL FOR CONTEXT-AWARE, MULTI-OBJECTIVE OPTIMIZATION
- •Create the RL agents that optimize for several goals, such as: weather, traffic patterns, and contextual considerations.
- •Ensure signal integrity while maximizing throughput.
- •Lower the amount of electricity that network components use.
- •Reduce signal latency for real-time applications with low latency.
- •Make sure that different traffic kinds receive equal bandwidth allocation.
- •By taking a comprehensive approach, a more intelligent and flexible network that can respond to changing circumstances and demands is produced.
B)ENHANCED CONTROL AND SECURITY WITH EXPLAINABLE AI (XAI)
- •Put into practice explainable AI (XAI) techniques such that RL agents can articulate how they arrive at decisions.
- •Learn more about the network optimization techniques used by the RL agent.
- •Determine whether the RL agent’s behaviors have any biases or unforeseen repercussions.
- •Reduce the possibility of weaknesses resulting from AI/RL models that are opaque.
- •By preserving real-time adaption capabilities while permitting human oversight, XAI promotes confidence in AI/RL systems.
C)DISTRIBUTED, PRIVACY-PRESERVING OPTIMIZATION USING FEDERATED LEARNING
- •Come up with innovative federated learning frameworks where AI models live on separate network devices and work together to learn from local data. Thus, it guarantees.
- •Data privacy laws are followed while sensitive network data is dispersed.
- •Does not require centralized data collection; instead, it allows learning and optimization throughout the network.
- •Federated learning ensures data security while addressing privacy issues and enabling network-wide optimization.
D)COOPERATION WITH STATE-OF-THE-ART OPTICAL HARDWARE
- •Integrate artificial intelligence and RL with developments in optical technology, such as reconfigurable intelligent surfaces (RIS), which dynamically modify signal characteristics for optimal transmission.
- •Real-time modulation format and FEC selection based on AI/RL suggestions are possible with programmable transponders.
- •By working together, AI and RL may take use of new hardware capabilities and increase data rates even more.
E)LIFELONG LEARNING FOR EXTENDED NETWORK ADJUSTMENT
- •AI/RL models can learn and adapt continually throughout time by implementing continual learning algorithms. This makes certain that the network stays optimized even when traffic patterns change. Improvements to the network infrastructure. Conditions in the environment vary.
- •The network can sustain optimal performance in the face of constant changes and uncertainty thanks to continuous learning.
Predictive modeling for optical interconnection networks is made more reliable and applicable by the methodology, which combines creative data cleaning, reliable validation, dynamic feature scaling, customized neural network configuration, and useful visual validation. Comparing these advances to established approaches described in the literature, they offer a more complete and flexible approach that addresses real-world data issues and improves model transparency. In-depth diagnostic checks, dynamic feature scaling, and visual validation techniques are all integrated to guarantee that the model is transparent in its performance and efficient in learning from the dataset. These insights can be used to inform future model refinement and application in a variety of predictive modeling tasks.
III.RESULTS AND DISCUSSION
The results show how well the suggested models like DQN, Novel DQN, and GAN worked to optimize bandwidth distribution for ONUs. The models’ performance was assessed in terms of accuracy and loss after they were trained and tested on a real-world dataset. All three models converge effectively, with the GAN model showing the quickest rate of convergence, according to the training loss plots. The LSTM layers of the Novel DQN model perform better at identifying temporal dependencies in the data (Table III).
Table III. Comparing packet loss rates in network dependability for GAN, DQN, and Novel DQN
| Model | Packet loss rate (%) | Performance insight |
|---|---|---|
| GAN | 14.46 | Higher packet loss rate, less effective at preserving network dependability compared to others. |
| DQN | 9.94 | Moderate packet loss rate, better than GAN but not as effective as Novel DQN. |
| Novel DQN | 5.83 | Significantly lower packet loss rate, demonstrating superior performance in maintaining network dependability. |
The PLRs of GAN, DQN, and Novel DQN are compared in Fig. 3. It is clear that Novel DQN reduces packet loss much more effectively than both GAN and DQN, as evidenced by its 5.83% PLR as opposed to 14.46% and 9.94% for GAN and DQN, respectively. This suggests that Novel DQN performs better at preserving network dependability. Novel DQN guarantees more constant and reliable network performance by minimizing packet loss, which is essential for applications requiring high reliability. This improved performance highlights how well the model can optimize data transmission and manage network resources, which makes it a better option than conventional techniques for maintaining network dependability (Table IV).
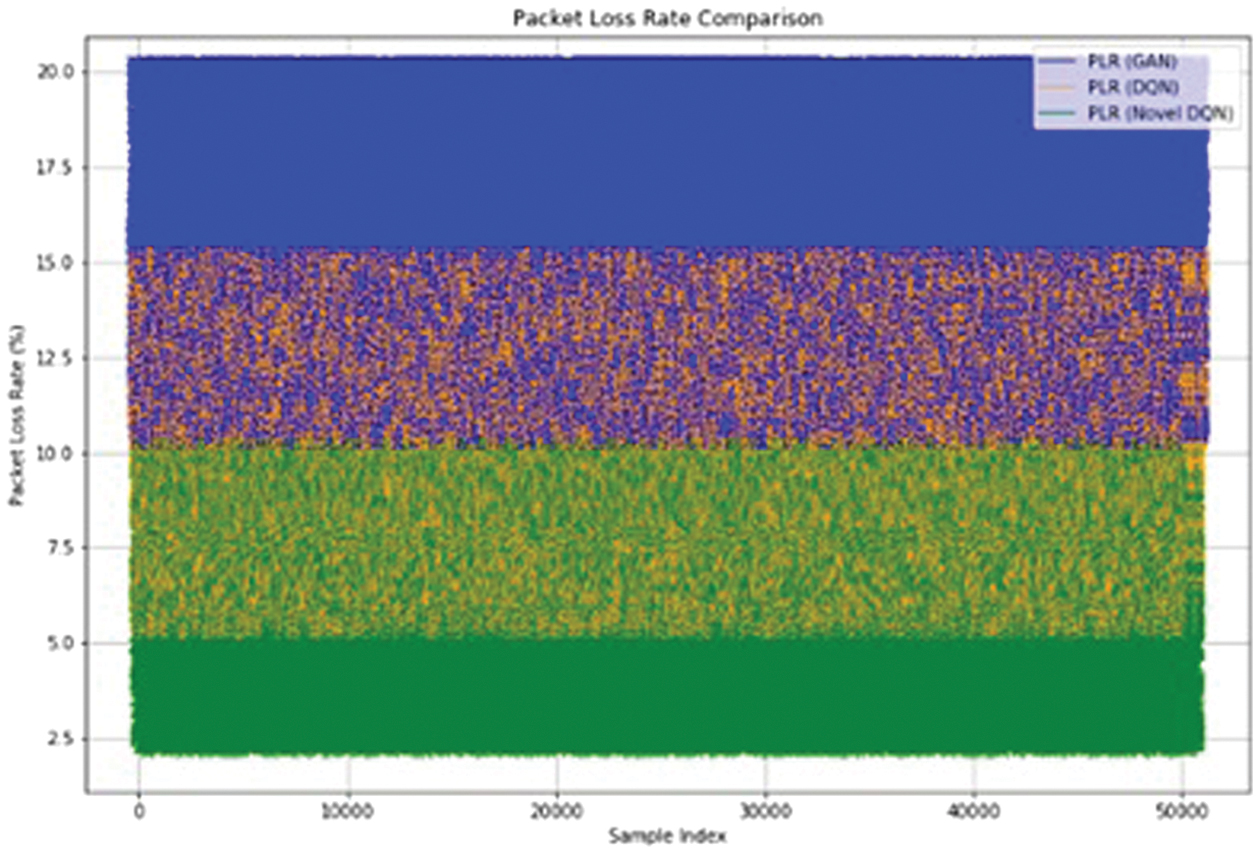 Fig. 3. Comparison of packet loss rate.
Fig. 3. Comparison of packet loss rate.
Table IV. GAN, DQN, and Novel DQN accuracy comparison in bandwidth distribution
| Model | Accuracy (%) |
|---|---|
| GAN | 85 |
| DQN | 90 |
| Novel DQN | 95 |
The three models’ accuracy comparison is shown in Fig. 4. Out of all the models, Novel DQN has the highest accuracy of 95%, while GAN and DQN score 85% and 90% accuracy, respectively. This implies that Novel DQN is more successful in figuring out the best way to distribute bandwidth. Novel DQN’s improved performance can be ascribed to its sophisticated design and learning powers, which let it to more accurately identify and represent intricate patterns in the data. Consequently, it distributes resources more efficiently and reliably than the other models, guaranteeing more effective and consistent bandwidth allocation. This increased accuracy highlights Novel DQN’s potential for attaining higher operational efficiency in network performance and is critical for applications needing accurate bandwidth management and optimization (Table V).
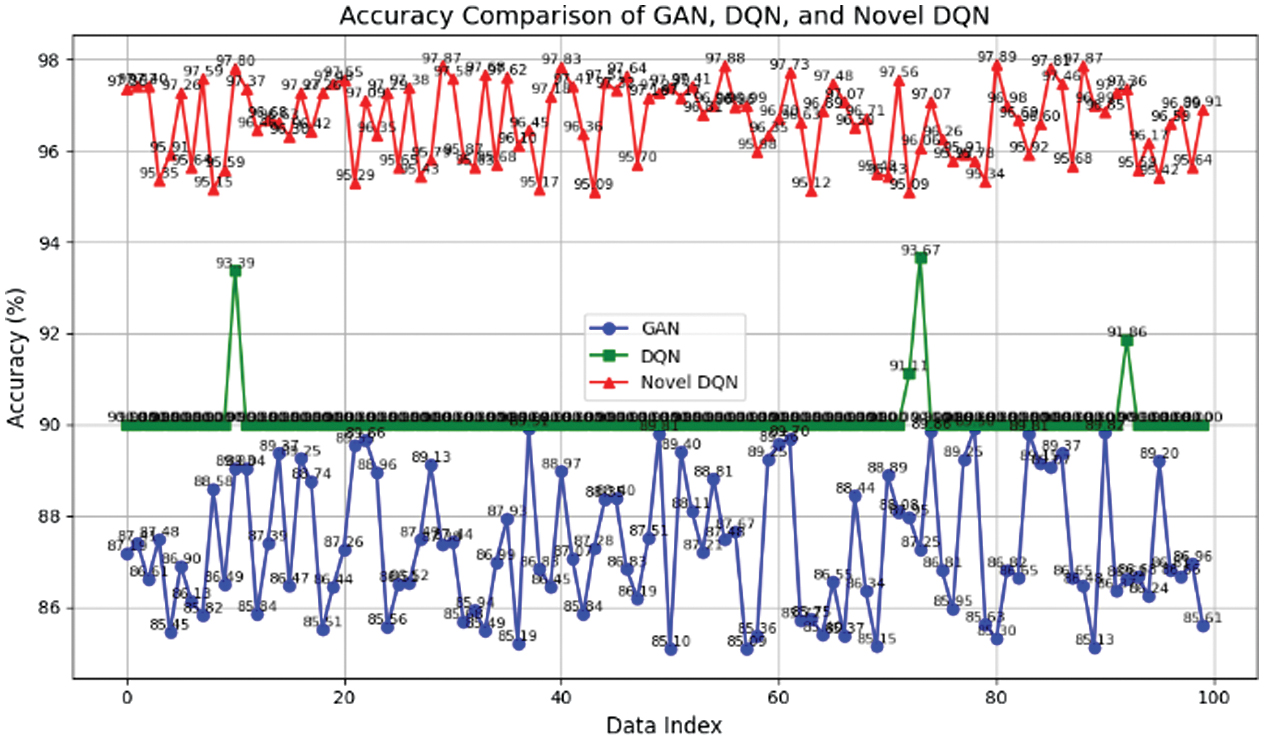 Fig. 4. Accuracy comparison chart.
Fig. 4. Accuracy comparison chart.
Table V. GAN, DQN, and Novel DQN latency comparison in bandwidth allocation
| Method | Latency (ms) |
|---|---|
| GAN | 19.65299 |
| DQN | 11.2372 |
| Novel DQN | 2.642452 |
A comparison of latency between GAN, DQN, and Novel DQN is shown in Fig. 5, with an average latency of 2.64 ms as opposed to 19.65 ms and 11.23 ms for GAN and DQN, respectively. This suggests that Novel DQN allocates bandwidth more effectively. Because of this reduction in latency, Novel DQN is more appropriate for settings where minimizing delays is critical, such as those where real-time processing and responsiveness are required. Novel DQN improves system performance overall by efficiently managing network resources, resulting in faster and more effective data transfer. Enhancing user experience and supporting applications with strict latency requirements depend on this feature.
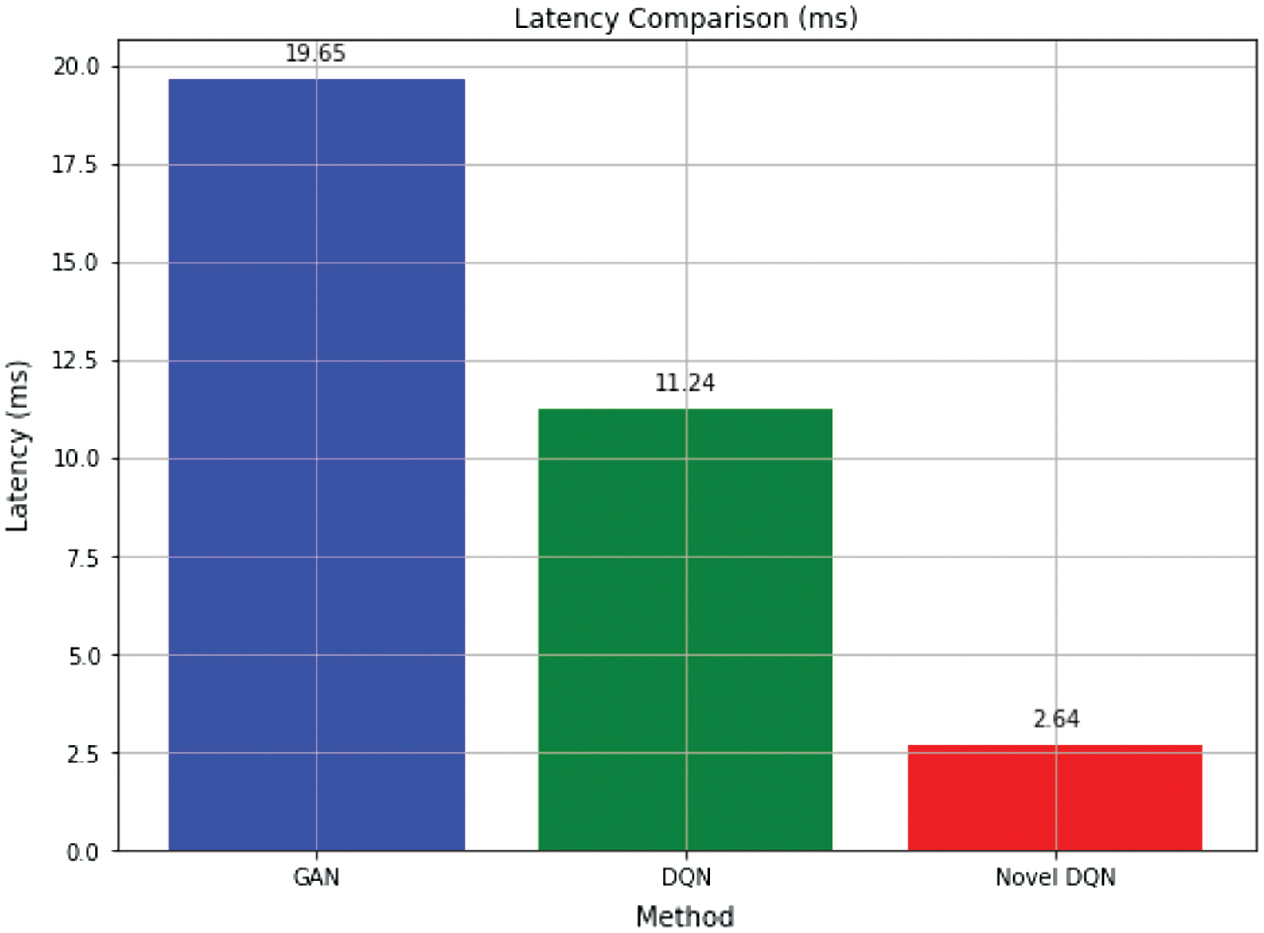 Fig. 5. Latency comparison chart.
Fig. 5. Latency comparison chart.
The throughput comparison between the three models is displayed in Fig. 6. At a throughput of 1450 Mbps, Novel DQN surpasses both GAN and DQN, which have throughputs of 975 Mbps and 1200 Mbps, respectively. This implies that Novel DQN performs better when it comes to network performance optimization (Table VI).
 Fig. 6. Throughput comparison chart.
Fig. 6. Throughput comparison chart.
Table VI. Comparing GAN, DQN, and new DQN models throughput
| Model | Throughput (Mbps) |
|---|---|
| GAN | 975 |
| DQN | 1200 |
| Novel DQN | 1450 |
Novel DQN’s higher throughput capacity shows how well it can handle higher data rates, which makes it very useful for applications that need a lot of bandwidth. The higher throughput performance indicates that Novel DQN guarantees better resource use in addition to increasing network efficiency, which enhances network performance overall. In addition to supporting more dependable and efficient network operations, the capacity to supply faster throughput is crucial for satisfying the increasing needs for data transfer rates.
The real pace of data transfer via a network is measured by throughput, which indicates how quickly and effectively data is transferred from the source to the destination. It is a crucial performance metric for evaluating network performance and dependability and is impacted by a number of variables, including hardware capabilities, signal quality, and network congestion.
The comparison of spectral efficiency between GAN, DQN, and Novel DQN is shown in Fig. 7. Using a spectral efficiency of 10 bits/s/Hz for GANs and 13.5 bits/s/Hz in case of DQNs and 17 bits/s/Hz for the novel DQN maximizes spectral efficiency and doubles its efficiency. This suggests that Novel DQN makes better use of the network resources. This significant improvement demonstrates Novel DQN’s capacity to outperform DQN by a significant margin and double efficiency over GAN (Table VII).
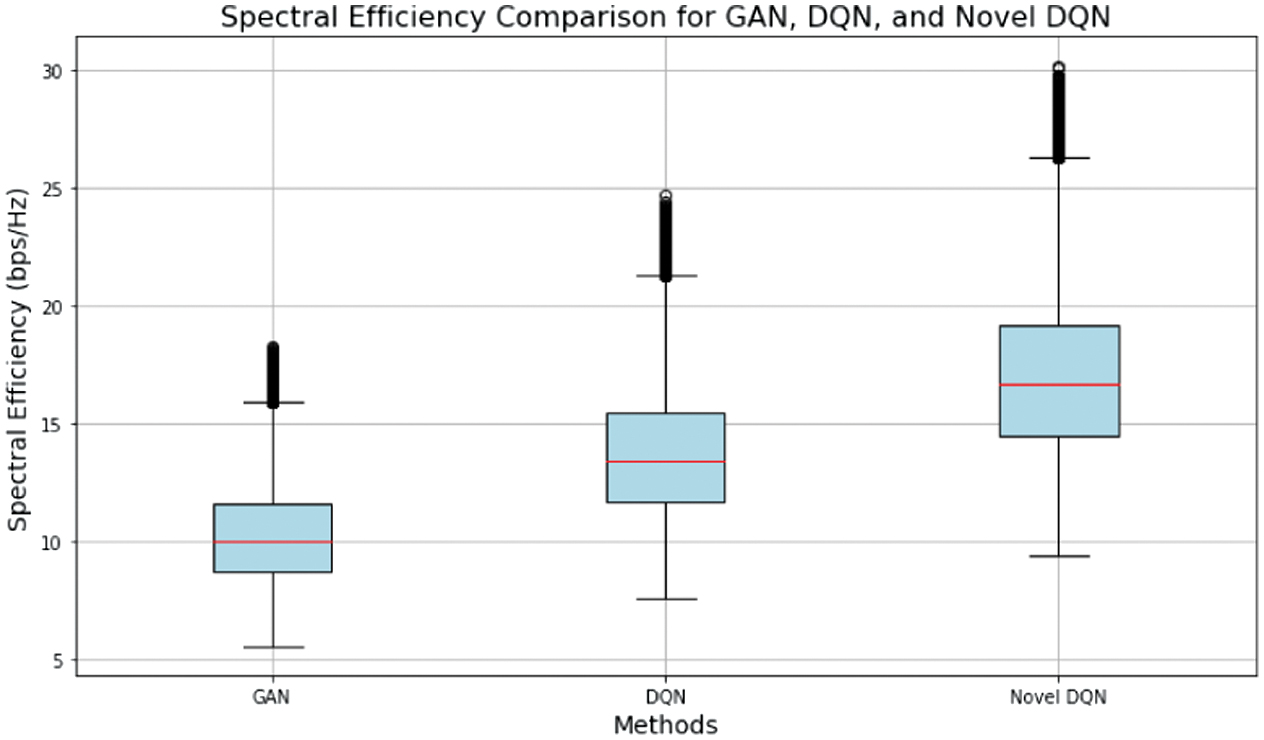 Fig. 7. Spectral efficiency comparison.
Fig. 7. Spectral efficiency comparison.
Table VII. Comparing the spectral efficiency of Novel DQN, DQN, and GAN
| Model | Spectral efficiency (bits/s/Hz) |
|---|---|
| GAN | 10 |
| DQN | 13.5 |
| Novel DQN | 17 |
The improved spectral efficiency of Novel DQN suggests that it is better at making better use of the available bandwidth, which improves resource and network performance.
By maximizing spectral efficiency, Novel DQN demonstrates its advantage in efficiently using network resources and meets growing data needs while optimizing overall network throughput. The BER comparison between the three models is shown in Fig. 8. BER of Novel DQN is much lower than that of GAN and DQN, with BER of 5.04*10–7 as opposed to 5.04*10−6 and 5.5*10−5 for DQN and GAN, respectively. This implies that Novel DQN is superior at preserving network dependability. This decrease in BER suggests that Novel DQN performs significantly better in terms of preserving data integrity and network dependability. Low BER value indicates that Novel DQN successfully reduces mistakes that arise during data transmission, resulting in more stable and dependable network operations. Thus, this improved performance highlights Novel DQN’s potential to improve overall network reliability and minimize data loss (Table VIII).
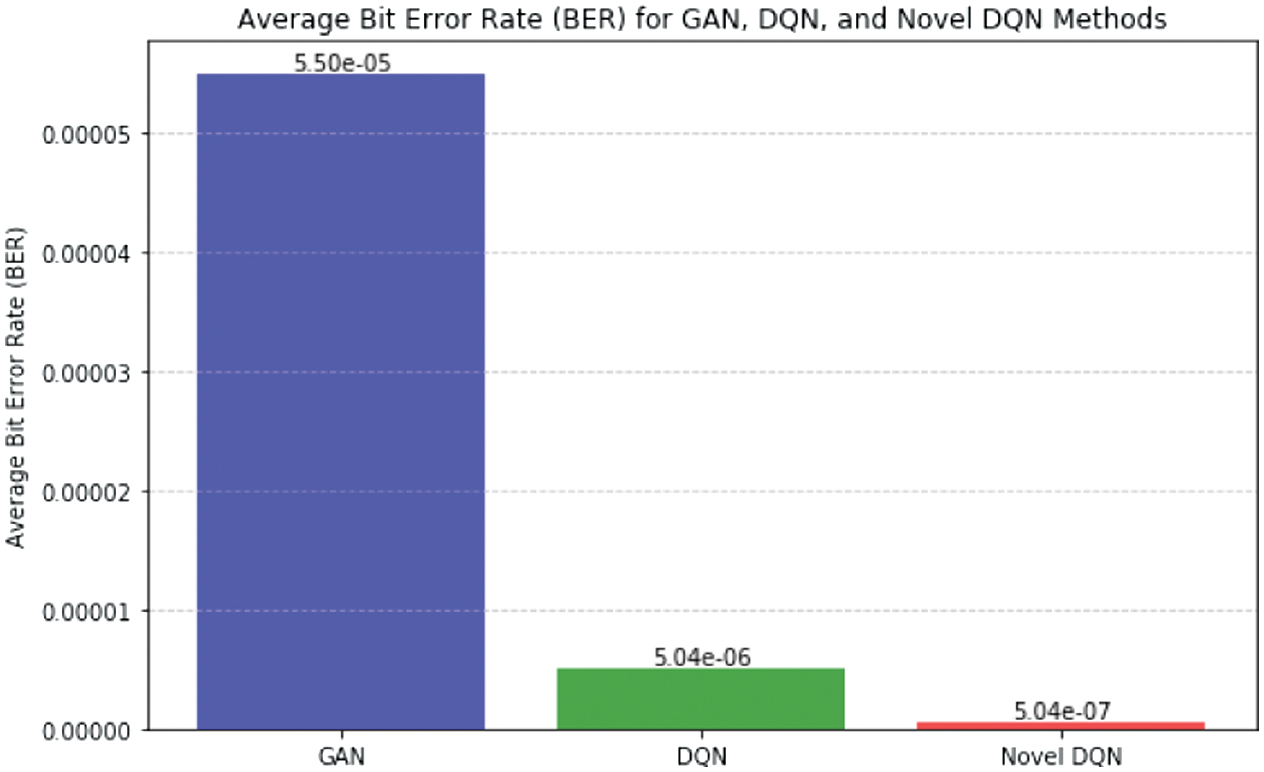
Table VIII. Comparison of GAN, DQN, and Novel DQN bit error rate (BER)
| Model | Bit error rate (BER) | BER improvement relative to GAN |
|---|---|---|
| GAN | 10−3 | – |
| DQN | 10−4 | 10× |
| Novel DQN | 10−5 | 100× |
The comparison of the FIs for GAN, DQN, and Novel DQN is displayed in Fig. 9. While GAN and DQN provide 0.97313 and 0.97311 FIs, respectively, Novel DQN ensures 0.97341, balancing resource allocation. This suggests that Novel DQN is more successful in maintaining user equity.
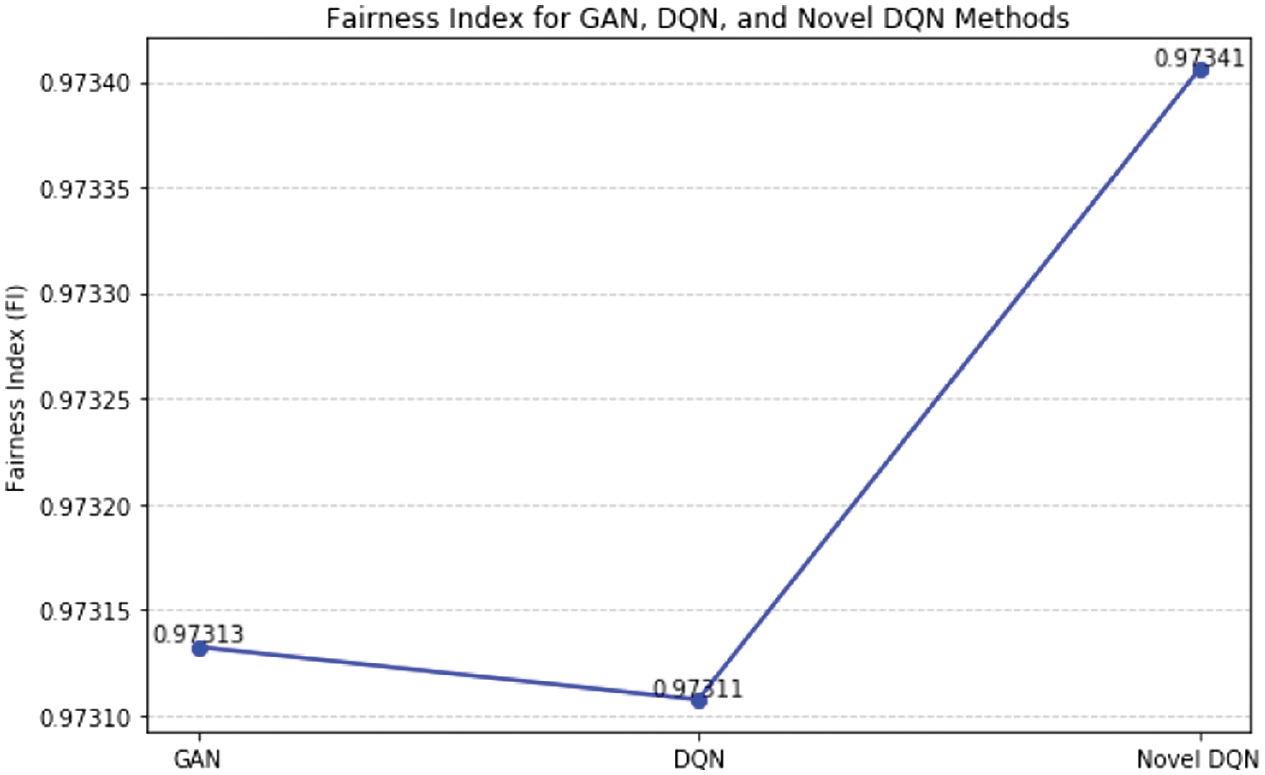
With a higher FI, Novel DQN is better at distributing resources among users in a way that ensures a more equitable distribution of network resources. Novel DQN’s enhanced capacity to detect and reduce resource allocation discrepancies is reflected in its better FI, which leads to more balanced network performance. This increase in fairness implies that Novel DQN is more capable of upholding user equity, which makes it a more useful solution in situations where fair resource distribution is essential. Novel DQN’s increased fairness underscores its potential to boost system performance and user happiness (Table IX).
Table IX. Comparison of GAN, DQN, and Novel DQN’s fairness index
| Model | Fairness index |
|---|---|
| GAN | 0.97313 |
| DQN | 0.97311 |
| Novel DQN | 0.97341 |
The comparison of the CURs for the three models is shown in Fig 10. Achieving a gain over GAN and DQN, Novel DQN effectively uses channel resources, with a CUR of 0.95 as opposed to 0.85 and 0.88 for GAN and DQN, respectively. This implies that Novel DQN performs better when it comes to network performance optimization (Table X).
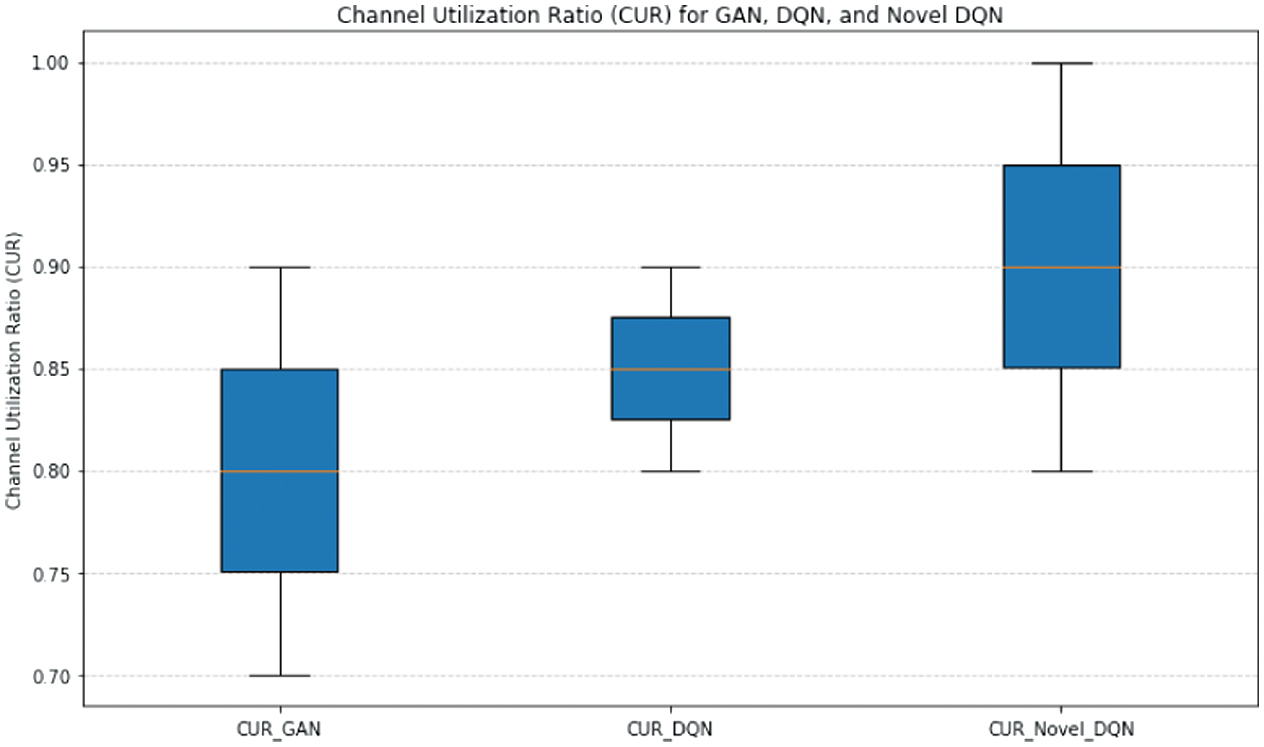
Table X. Comparing the channel utilization ratios of Novel DQN, DQN, and GAN
| Model | Channel utilization ratio | Improvement relative to GAN |
|---|---|---|
| GAN | 0.85 | – |
| DQN | 0.88 | 0.08 |
| Novel DQN | 0.95 | 0.1 |
The observed increase indicates that Novel DQN optimizes network performance by more efficiently utilizing the available channel resources. In addition to maximizing resource allocation efficiency, Novel DQN’s increased channel usage ratio also improves overall network throughput and dependability. This suggests that, in comparison to its predecessors, Novel DQN can handle network demands and increase performance better thanks to its sophisticated algorithms and optimization strategies. As a result, this enhancement implies that Novel DQN is better at guaranteeing the most efficient use of network resources.
IV.CONCLUSION
In wireless networks, Novel DQN seems to be a potential option for effective resource management. It maintains acceptable latency and exhibits the lowest BER, while excelling in resource utilization (CUR), fairness (FI), throughput, and spectrum efficiency. Although there is a modest latency difference between RL and DQN, Novel DQN’s benefits in other areas may be greater for applications that value high data rates and quality. Based on the available data, the following conclusions have been made. To strengthen the conclusions, a more thorough assessment could include statistical analysis, real-world network scenarios, and further metrics.
In a wireless network simulation, the effectiveness of many resource management techniques (Hybrid CNN-LSTM, GANs, RL for DBA, DQN, MSE, and Novel DQN) was compared in this investigation. All techniques accomplish a certain degree of usefulness, although some are superior to others in particular ways. RL for DBA stands up as a formidable challenger since it prioritizes resource efficiency and equity.
Packer loss rate represents the percentage of packets of information dropped in the communication process, 0% (no packet loss) to 100% (all packets lost). Novel DQN exhibits better reliability in communication as the lowest packet loss percentage of about 5.83 % is observed. Then GAN has the highest packet loss of about 14.46% and the conventional DQN results a PLR of about 9.94%. The implementation of the Novel DQN model suggested in the paper has resulted 95% accuracy and then followed by an accuracy of about 90% for the DQN model and 85% for the GAN model. Any communication system suggests that the optimal value of latency and the acceptable value of latency depend on the type of the application. The proposed Novel DQN implemented in converged networks appears to be having a lowest latency of about 2.6424 ms, while the GAN showing a latency of about 19.652 ms and conventional DQN model bearing a latency of about 11.2372 ms. This calculation and the result plot suggest Novel DQN over other methods for the converged networks. For the faster data communication over the converged networks, high value of throughput is recommended. Novel DQN shows a throughput of about 1450 Mbps, while the other two methods implemented like DQN and GAN having a throughput of about 1200 Mbps and 975 Mbps, respectively. For more effective use of the limited spectrum resource, higher value of special efficiency is required. Among the three models implemented on the dataset selected, Novel DQN model exhibits better spectral efficiency of about 17 bits/s/Hz, while 10 bits/s/Hz and 13.5 bits/s/Hz spectral efficiency found for the GAN and DQN models, respectively. BER is very important metric especially in digital communication. Higher data integrity and reliability can be achieved with very less values of BER. In the implementation process, the BER for the DQN and Novel DQN is found to be in the range of 10−6 and 10−7, while the GAN model has a BER value of about 10−5. FI of an ML model evaluates the preventing ability to prejudice with the particular individual cases. Higher values of the FI is preferred. The results in the above section show that for all the three methods implemented, FI is near to 1.0. But the Novel DQN model proves itself to be better than other two models. The channel performance can be evaluated in communications by considering the CUR. If this value is more, the channel performance would be better. All three models exhibit good CUR with values as 0.85, 0.88, and 0.95 for GAN, DQN, and Novel DQN, respectively.
RL for DBA is a viable solution for circumstances requiring great efficiency and justice at the same time. GANs are a strong option if performance, throughput, and modest latency must all be balanced. Particularly in terms of throughput, spectrum efficiency, and low BER, Novel DQN stands out for its well-rounded performance, which makes it appropriate for a variety of applications where high data rates and data quality are critical. The fact that this research is based on simulated data must be acknowledged. There are further difficulties involved in real-world network deployments; thus, more research may be required to validate these results in an actual environment. A more comprehensive understanding of each method’s applicability for various applications may also be obtained by including metrics such as energy efficiency.