I.INTRODUCTION
The educational scene is transforming substantially because of AI technologies that are redefining classroom methods [1–5]. In language education, the potential and limitations of AI are pronounced due to the intricacies of language acquisition and assessment [6–9]. Because of the rapid adoption of large language models (LLMs) (ChatGPT, Claude, etc.), researchers and scholars are investigating various ways to automate assessment to lighten the load of assessment and provide faster feedback [10–12]. However, empirical evaluation in this area remains preliminary [13,14].
German presents particular challenges for assessment due to its case system, grammatical gender, and extensive use of compounding. We thus examine general-purpose LLMs and a fine-tuned local model on authentic exam papers in a German teacher education program and ask:
RQ1. How accurately can general-purpose LLMs evaluate in-program exams when given pre-corrected samples as references?
RQ2. How well does a fine-tuned local model score student responses against reference answer lists?
RQ3. How do AI-based techniques compare with traditional human grading, including a newly developed overlay method?
RQ4. Which integration strategies balance accuracy, efficiency, and usability in test assessment?
The remainder of this paper is structured as follows. Section II reviews prior research on technology-assisted language assessment, LLMs in education, and fine-tuning approaches for domain-specific evaluation tasks, with particular attention to German language assessment. Section III describes the research design, dataset, assessment conditions, and analytical procedures. Section IV presents the empirical results addressing accuracy, reliability, efficiency, and usability across human and AI-based grading methods. Section V discusses the findings in relation to methodological constraints and pedagogical implications. Finally, Section VI concludes the paper by summarizing key contributions, limitations, and directions for future research.
II.RELATED LITERATURE
A.EVOLUTION OF TECHNOLOGY IN LANGUAGE ASSESSMENT
Language education technology has transitioned over the last three decades, from early behaviorist Computer-Assisted Language Learning (CALL) to engaging, data-informed, and immersive platforms [15–21]. AI made ASR-based feedback and adaptive platforms possible [22], but it has also come with concerns over data privacy, equity, and teacher readiness and willingness to change [23–25]. Strength of evidence indicates that hybrid approaches, where human pedagogy is combined with technology, are preferable [16,21,25,26].
B.LARGE LANGUAGE MODELS AND THEIR EDUCATIONAL APPLICATIONS
AI is reshaping instruction and assessment through personalization and feedback speed [27–32]. Assessment using LLMs has shown promise but lacked coherence, cultural context, and complex domain-specific tasks [33–39]. Performance is language-specific due to dataset differences; non-English and minority languages tend to not perform as well [35,40,41]. German had intentions—results are mixed and task-dependent [42–44].
C.FINE-TUNING FOR SPECIALIZED EDUCATIONAL TASKS
Fine-tuning has the potential to enhance task alignment and efficiency with small domain datasets [45–47]. Curriculum/domain adaptation and adapter-based methods provide opportunities for resource constraints [48,49] and have reported improvements in educational scoring tasks [50,51]. Overall, practical implementation of fine-tuning is dependent on a reliable data pipeline (OCR/multimodal), interface input, and input data quality—voids that can offset fine-tuning benefits theoretically [52,53].
D.ASSESSMENT IN GERMAN LANGUAGE TEACHING
German has a particularly complicated structural intricacy, with its case system, gendered articles, and inflectional morphology of words, which makes it especially challenging with respect to instruction and assessment [54,55]. These complexities often add cognitive load and complicate the assessment of learners’ writing [56]. Although standardized DaF exams test multiple competencies, that is not true for language teacher education at the university level, which often prioritizes open-ended, information-rich exams [57]. Recent developments in automated assessment (e.g., G-SciEdBERT) have aimed to help teachers to assess the German language [43,58]. However, results have been mixed, especially for complex and natural writing. This work is not about standardized DaF tests or grammar assessment schemes—this is about using a general or fine-tuned LLM for assessing authentic midterm assessments in German teacher education. This study also extends the literature that is developing as it addresses technical and pedagogical shifts in the deployment of AI in classroom-based language assessment [59–62].
Fine-tuning pretrained models on narrower and specific datasets can enhance their capability and performance for specific tasks and contexts (e.g., [45]). This offers flexibility and opportunity for tuning powerful generic models that would cost far more to operationalize based on scratch. For example, fine-tuning language models for education improves both the efficiency and contextual relevance of AI-based solutions. Fine-tuning LLMs for educational context enhances both efficiency and contextual relevance of AI-based solutions, particularly for automated assessment and feedback [45]. This is illustrated through the assessment of STEM education with GPT-3.5, where results indicate 9.1% better accuracy compared to baseline models [51]. The evidence suggests that fine-tuning is most beneficial when language and contextual details are critical of the domain. Suggestions for curriculum domain adaptation and adapter-based fine-tuning address the issues of client resources and overfitting [63]. The suggestions balance work efficiency through data difficulty ranking with unsupervised adaptation or modular trainable layers that maintain general knowledge and tweak networks’ behavior [48,49]. The fine-tuning method is of utility in many fields, enhancing language models for machine translation, information extraction, cross-linguistic performance, and a wide range of tasks [64,65]. Assessment modeling in interactive learning systems involves, for example, modeling assessment that predicts a pedagogical assessment based on learner–system interaction data as a pretraining task for improving adaptiveness and reduce dependence on labeled data [66]. General and domain-specific model efficacies were balanced based on the data curation and modeling standards, as well as systematic evaluation and assessment of model architecture and learning development/evolution [67]. Thus, the fine-tuning process provides a flexible and extensible basis for harmonizing AI tools about the complicated context of evaluation in education. The field testing of such applications is especially challenging in limited-resource locations. The current study demonstrates that local fine-tuning models do not yield reliable, usable results without technical support and stability of the input pipelines (e.g., OCR) and accurate, high-quality annotated training data. The theoretical potential of fine-tuning in education needs ongoing infrastructure support and sustained supervising and controlled contextual evaluation to become practical (e.g., [52,53,68]).
III.METHODOLOGY AND PROCEDURES
A.RESEARCH DESIGN
Using a comparative experimental design with the Faculty of Education at Anadolu University, we have compared (1) automated scoring with general-purpose LLMs, (2) an overall locally fine-tuned (LLaMA-based) model, and (3) human grading with regular keys and with an overlay method.
B.Dataset
Ten actual anonymized midterm response papers from “Approaches to Foreign Language Teaching” (more than 50% multiple-choice items) are used. All PII and ethical permissions were submitted and obtained per institutional ethics. AI-based approaches are presented structured inputs through standardized answer keys provided by the university. General-purpose LLM performance was moderate; the local model was limited by the interface and poor visual/OCR, resulting in limits to comparability.
The dataset size was intentionally limited to 10 exam papers because this study was designed as an exploratory pilot investigation aimed at identifying comparative performance patterns rather than producing statistically generalizable claims. The selected papers were drawn from fully completed and legible midterm exams and were considered representative of typical student performance within the course. This controlled sample enabled a detailed, methodologically transparent comparison of human and AI-based scoring behaviors under identical assessment conditions.
Although more than half of the exam consisted of multiple-choice items, these items were not limited to surface-level factual recall. Instead, they required learners to process morpho-syntactic structures, grammatical agreement, and contextual interpretation, which are central challenges in German as a foreign language. Consequently, the assessment construct targeted in this study encompasses linguistic decision-making processes embedded in authentic exam conditions rather than exclusively open-ended writing performance.
C.ASSESSMENT APPROACHES
General-purpose LLMs are ChatGPT-5, Claude Opus 4.1, Gemini Advanced 2.5 Pro, DeepSeek Pro, Qwen-3 Max, and Mistral Le Chat Pro. The inputs include (a) a scan of the answer sheet, (b) the answer key/list of textual reference answers, and (c) student sheets, both graded and ungraded (text/image). The grading methods include (1) task + criteria, (2) criteria + graded examples with full explanations, and (3) a collection of ungraded student responses. No explicit programming of rubrics is used; instead, we stimulate pattern recognition and contextual reasoning.
The fine-tuned local model, LLaMA 3.3 70B Instruct, was trained on a set of 142 graded midterms (LM Studio v0.3.14; 10 epochs; lr = 5e-5; batch size = 16; AdamW) [69–71]. At inference, the model received keys and returned intended scores and rationale. At the time of writing this (i.e., two months after reviewing), the model did not output usable data due to OCR/visual parsing and interface limitations.
This condition was intentionally retained in the study to evaluate the practical feasibility of deploying a locally fine-tuned LLM in an authentic, resource-constrained educational setting. Accordingly, the fine-tuned LLaMA condition functions as a feasibility and stress-test case rather than as a fully comparable scoring condition, allowing the study to empirically document infrastructural and pipeline-related barriers that may undermine the benefits of fine-tuning in real-world assessment scenarios.
Human grading. Two experienced DaF instructors graded independently using the answer keys and rubrics (tracked time). The overlay method involved corresponding intervals with publishers’ transparent layers with correct selections for visual centering in case of concision and visual/recognition accuracy (ultimately prioritizing scoring accuracy and usability over precise timing measurements).
IV.DATA COLLECTION AND ANALYSIS
The assessment performance evaluation examined three fundamental elements which included accuracy alongside efficiency and reliability. Accuracy: Each evaluation method received accuracy assessments through comparison with a gold standard score that two experienced instructors generated together. The “gold standard” represents a widely recognized benchmark that serves as a reference point for comparative validation in educational assessment research [72,73]. Accuracy metrics included:
- •The comparison between each evaluation method and the gold standard score used percentage agreement as its metric.
- •Cohen’s kappa coefficient to assess interrater reliability [74,75].
For the purposes of this study, Cohen’s κ was calculated at the total-score level after scores were mapped to discrete agreement categories, enabling categorical comparison between each AI-based scoring output and the human gold standard. This approach was adopted to assess systematic agreement patterns rather than to model continuous score deviation, which was separately captured through root mean square error (RMSE).
- •RMSE calculated the mean distance between predicted scores and gold standard values.
RMSE functions as a common evaluation metric for models because it works best with Gaussian error distributions. The squared error component in RMSE enhances its sensitivity to large deviations while increasing penalties for such deviations [76–78]. Efficiency and reliability: The evaluation time required to examine each paper served as the main efficiency measurement. The total evaluation time for AI-based methods consisted of processing time for model output generation and human intervention time for input formatting and result interpretation. Human evaluators directly assessed papers without needing additional methods. The overlay method sought to expedite evaluation through visual alignment but did not obtain any formal timing data. The institution paid human raters for their complete time spent on each paper according to standard research participation compensation rules.
V.RESULTS
This section outlines the findings from the study that examined research questions RQ1–RQ4 that related to accuracy, efficiency, and usability of evaluation approaches that incorporated AI and human evaluations of German language examinations.
RQ1: How accurately can general-purpose LLMs evaluate in-program examinations in a German teacher education context by comparing them to pre-corrected samples? Accuracy was evaluated against a gold standard constructed by two human evaluators with expertise in research on German language pedagogy. All RMSE values reported in this study were calculated based on total exam scores, with the maximum achievable score set at 100 points. RMSE therefore represents the average absolute deviation of each scoring method from the human gold standard on the full-exam scale, allowing direct interpretability of error magnitude across human and AI-based evaluation approaches. Against the human gold standard, we obtained (see Figs 1 and 2):
- •ChatGPT-5: RMSE = 5.000, κ = 0.344
- •Claude Opus 4.1: RMSE = 6.480, κ = 0.249
- •Gemini Adv. 2.5 Pro: RMSE = 7.424, κ = 0.028
- •DeepSeek Pro: RMSE = 8.485, κ = 0.033
- •Qwen-3 Max: RMSE = 4.690, κ = –0.018
- •Mistral Le Chat Pro: RMSE = 5.385, κ = –0.164
Percentage agreement complements these metrics (see Table I):
Human grading achieved 98% accuracy. Among the LLMs, Qwen 3 Max (78%) performed best, followed by ChatGPT-5 (75%) and Mistral (71%). However, higher agreement does not always imply higher κ; negative κ values indicate systematic deviation from human decisions.
The performance of ChatGPT-5 metrics for output is the most balanced overall, while Qwen-3 Max had the highest percent agreement at 78%; ChatGPT-5 is next at 75%, followed by Mistral at 71%. The models with high percent agreement show inconsistency in the same response alignments among question types and have low interrater agreement reliability. Some of the models with negative kappa values indicate that they systematically disagreed with the human gold standard. Ideally, the LLMs sometimes come up with the right answer, yet collectively their measure of reliability was limited overall.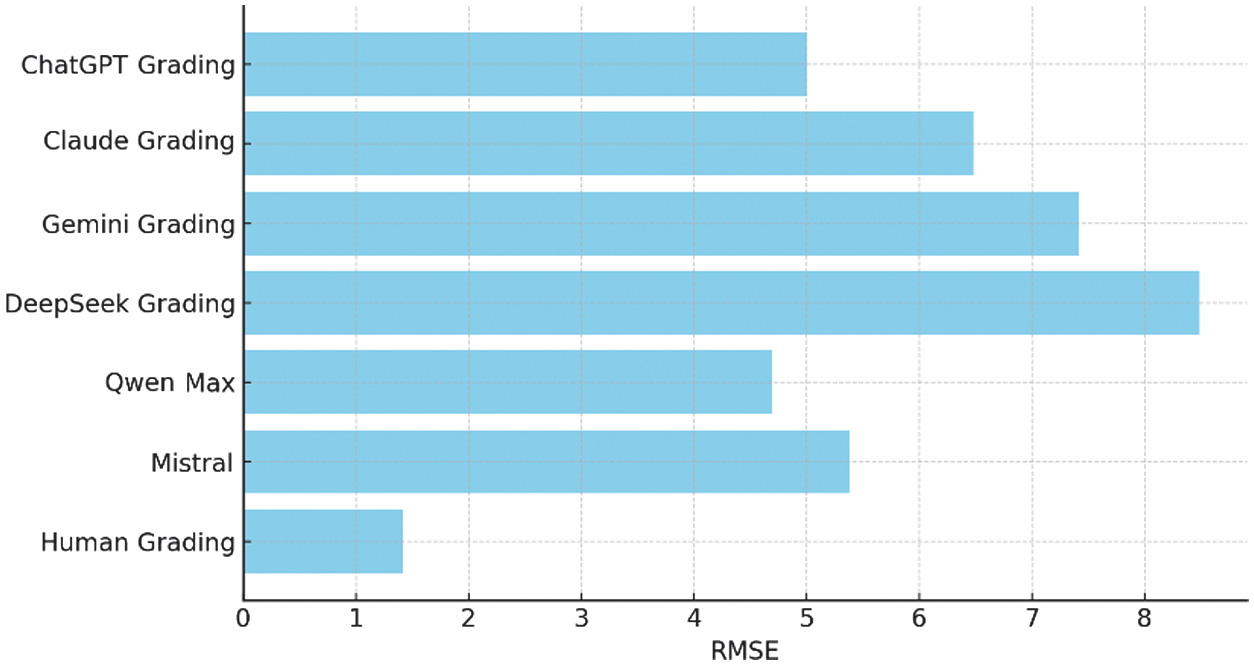 Fig. 1. RMSE of assessment methods compared to reference grading.
Fig. 1. RMSE of assessment methods compared to reference grading.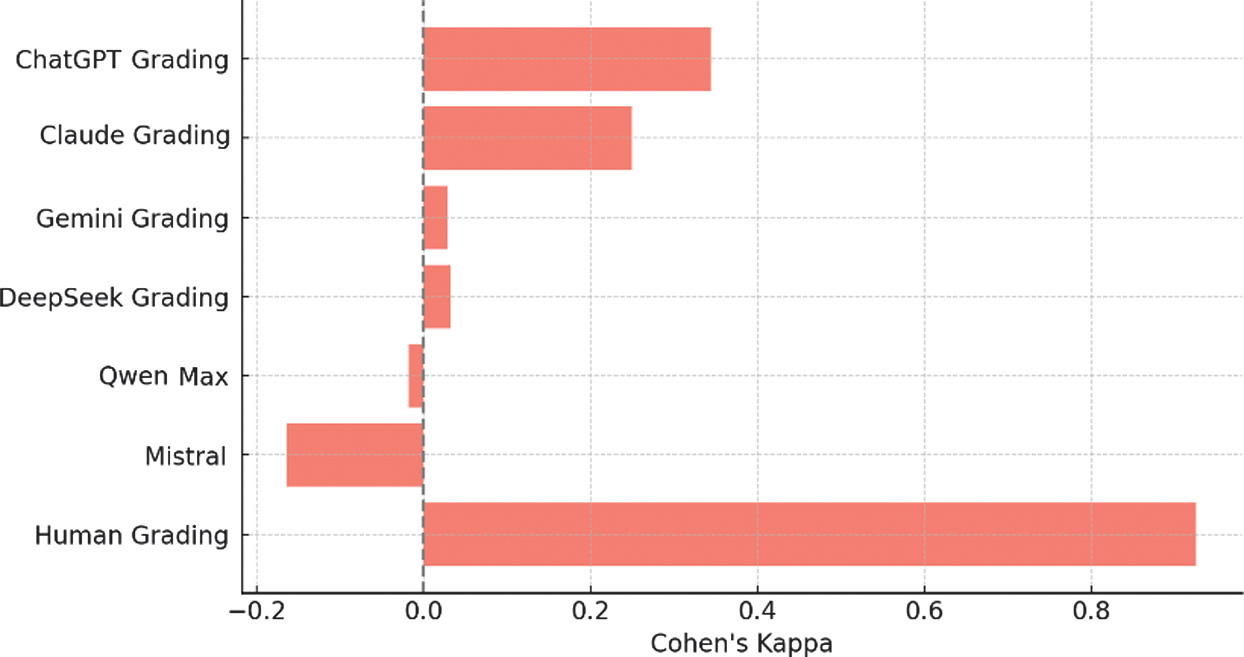 Fig. 2. Cohen’s kappa of assessment methods compared to reference grading.Table I. Accuracy metrics of AI and human grading compared to reference grading
Fig. 2. Cohen’s kappa of assessment methods compared to reference grading.Table I. Accuracy metrics of AI and human grading compared to reference grading
| Evaluation method | Percentage agreement (%) | RMSE | Cohen’s kappa |
|---|---|---|---|
| Human grading | 98 | 1.414 | 0.926 |
| Qwen-3 Max | 78 | 4.690 | −0.018 |
| ChatGPT 5 grading | 75 | 5.000 | 0.344 |
| Mistral Le Chat Pro | 71 | 5.385 | −0.164 |
| Claude Opus 4.1 | 58 | 6.480 | 0.249 |
| Gemini Adv. 2.5 Pro | 45 | 7.424 | 0.028 |
| DeepSeek Pro grading | 28 | 8.485 | 0.033 |
RQ2—Fine-Tuned Local Model
The local LLaMA 3.3 70B model fails to complete scoring; RMSE/κ cannot be computed. Primary causes are absent OCR integration, unstable visual parsing, and LM Studio interface limitations. Fine-tuning alone is insufficient without a robust multimodal pipeline. As a result, Research Question 2 could not be answered empirically in terms of quantitative accuracy or reliability metrics. The absence of valid model outputs precluded statistical comparison with human or general-purpose LLM scoring results, and the findings related to RQ2 are therefore restricted to feasibility-level observations rather than performance-based evaluation.
RQ3—Human vs. AI Methods
Human methods are most reliable: RMSE = 1.414, κ = 0.926. The overlay technique matched conventional accuracy and—based on qualitative observation—reduced cognitive load and sped up operations (though not formally timed).
RQ4—Integration, Efficiency, Usability
- •Approximate end-to-end times per paper:
- •Human (conventional): ∼3.5 min
- •LLMs: 15–30 s model latency, but ∼2–3 min including prompt prep and verification
- •Overlay: fastest human method (not formally timed)
- •Fine-tuned LLaMA: >30 min with no valid output
Usability: Overlay = intuitive/low error; LLMs = verification needed; local model = unworkable under current constraints.
VI.DISCUSSION
A.COMPARATIVE EFFECTIVENESS OF ASSESSMENT APPROACHES
Results confirm prior work: educational AI requires domain-specific adaptation and stable input pipelines [79–83]. Despite moderate performance in places (e.g., ChatGPT-5 κ = 0.344), LLMs were unreliable on linguistically nuanced items. The local model illustrates deployment barriers: absent OCR/multimodal support can nullify fine-tuning gains. Human grading remains the most dependable approach; the overlay method is a pragmatic enhancement that preserves accuracy while improving speed and assessor comfort. In the short term, human-in-the-loop workflows are the most sensible path. Importantly, the fine-tuned local LLaMA condition should not be interpreted as evidence against the theoretical value of fine-tuning itself. Rather, the failure to obtain usable outputs highlights the dependency of fine-tuned models on stable OCR, multimodal input pipelines, and interface reliability. In this respect, the RQ2 findings contribute methodological insight by demonstrating that infrastructural limitations can invalidate otherwise well-aligned fine-tuning strategies in applied educational assessment contexts.
B.PRACTICAL IMPLICATIONS FOR LANGUAGE TEACHING
In practice, general-use LLMs should primarily be used for formative purposes (e.g., quick screening and draft feedback). High-stakes and summative grading should not rely on LLMs without human supervision, they should not use an LLM [84]. When institutions explore fine-tuned models [85,86], the best starting points are to invest in tested OCR and multimodal input pipelines, sturdy and reliable interfaces, and the development of high-quality, annotated datasets. To offload work but maintain some fidelity in multiple-choice-heavy environments, the overlay templates should be normalized at the institutional level and shared across courses. Finally, requisite programs should determine explicit human verification points and stipulated guidelines that ensure the validity, fairness, and teacher’s pedagogical integrity are ensured throughout the assessment process.
C.FUTURE DIRECTIONS FOR AI IN LANGUAGE ASSESSMENT
Future research should focus on explainable AI (XAI) scoring rationales that educators and stakeholders can build trust in and that can help identify mistakes. A combination of AI and human raters should be utilized: AI can score objective items, while human raters evaluate subjective or multifaceted responses. The optimal form of hybridization should be determined based on empirical evidence [38]. It is also necessary to produce customizable, teacher-facing tools for non-programmers to help localize models to their curriculum and assessment style. Finally, we need to ramp up multilingual training and evaluation protocols to mitigate data volatility and cultural misalignment in order to establish reliability of these non-English contexts.
VII.CONCLUSION
This study demonstrated that, while AI-based assessment methods provided efficiency gains, they did not achieve the level of grammatical sensitivity, syntactic awareness, and linguistic nuance required for valid language assessment. General-purpose LLMs exhibited inconsistent performance, and the fine-tuned local model did not yield usable results due to infrastructural limitations in OCR and multimodal processing. In contrast, human grading—particularly when supported by the overlay technique—achieved the most reliable balance between accuracy and efficiency. These findings underscore that, under current technological conditions, human-centered and hybrid assessment systems represent the most justifiable and methodologically sound approach for evaluating language learning outcomes.
VIII.RECOMMENDATIONS
Utilize a hybrid assessment: use LLMs to pre-assess or mark structured items with human involvement; use trained instructors for subjective/open-ended items. Invest in an input path with OCR for scanned/handwritten documents, and also take advantage of the XAI component to justify assessments and reveal mistakes. Train teachers with technology for ethical and efficient AI use, and allow for low-tech human augmentation (e.g., overlay) as a scalable, cost-effective enhancement.